


[Résumé] Dans cet article, vous allez découvrir pourquoi le nettoyage des données est une étape essentielle avant toute analyse ou modélisation, et comment les erreurs — doublons, valeurs manquantes, anomalies ou fautes de saisie — peuvent fausser complètement un résultat. Nous explorons différentes techniques modernes, allant d’outils comme Dedupe ou DeepMatcher jusqu’aux approches deep learning pour l’imputation ou la détection d’anomalies. Vous verrez également comment choisir la méthode la plus adaptée à votre dataset afin de construire un pipeline de données fiable, robuste et réellement exploitable.
Avant de se lancer dans la modélisation ou l’analyse, une étape s’impose : le nettoyage des données. Trop souvent sous-estimée, cette phase est pourtant cruciale pour garantir la fiabilité des résultats, éviter les biais, et construire des modèles robustes. Un dataset mal nettoyé peut induire des erreurs d’interprétation, fausser des prévisions, ou encore altérer les performances d’un modèle de machine learning.
Par exemple, lors d’une analyse de données médicales, un patient avec un âge enregistré à 150 ans est probablement une erreur de saisie (au lieu de 15 ans). Pourtant, si cette valeur est conservée, elle peut fortement influencer les statistiques ou la prédiction de maladies liées à l’âge. Et le pire, c’est que ces erreurs ne sont pas toujours visibles immédiatement. Un modèle peut sembler bien fonctionner. . . jusqu’à ce qu’un cas particulier mette en lumière ses failles. Mais d’où viennent ces erreurs ? Plusieurs sources sont possibles.
Ces erreurs peuvent avoir plusieurs origines, parmi lesquelles :
• Fautes de frappes: inversion de caractère, erreur d’accent, doublons, faute de ligne…
• Erreur de mesure: capteur imprécis ou d´efectueux, pannes ponctuelles…
• Valeurs aberrantes: une donnée valide en apparence mais qui s’éloigne du reste, ce sont des anomalies.
Ces anomalies (ou outliers) sont parmi les erreurs les plus délicates à détecter et à corriger. Elles ne sont pas forcément erronées, mais peuvent perturber fortement une analyse.
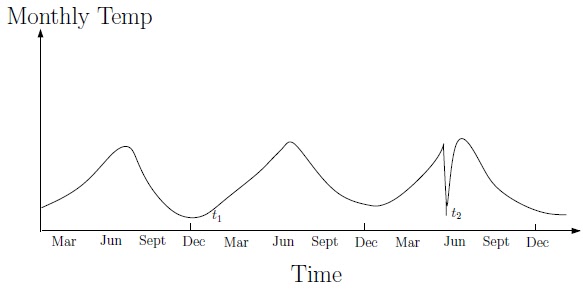
Un exemple typique d’anomalie météorologique
Sur cette exemple, une chute brutale de température en plein mois de juin attire l’œil (t2). Ce froid n’a rien d’inédit pour un mois de d´ecembre, mais il surprend pour un mois d’été. Est-il pertinent de conserver cette donnée pour les prédictions du reste du mois ? Est-ce un évènement météorologique rare mais explicable, ou simplement une erreur de capteur ? Ce sont exactement le type de questions que le data cleaning permet de résoudre.
Copie ou vraie donnée ?
Dans un jeu de données, toutes les répétitions ne se valent pas : certaines sont de simples doublons redondants, tandis que d’autres traduisent de réelles observations. Savoir les distinguer est l’un des aspects clés du nettoyage des données. En effet, des doublons peuvent biaiser l’apprentissage d’un modèle d’intelligence artificielle et l’amener à surpondérer certaines occurrences. On distingue deux types de doublons :
• Une duplication de ligne: une copie conforme d’une entité
• Doublon logique: deux enregistrements différents d´esignant la même entité.
Détecter une duplication exacte est relativement simple : un script peut repérer les lignes identiques dans un jeu de données. En revanche, les doublons logiques sont plus complexes à repérer, car leur détection repose souvent sur des connaissances externes. Le véritable défi consiste à enseigner à un modèle qu’ ”United States”, ”USA” et ” ´Etats-Unis” désignent une même entité, afin de généraliser cette logique à d’autres cas similaires. Pour cela, nous avons testé deux méthodes modernes. La première : Dedupe.
1) Dedupe
Dedupe est un framework open source conçu pour identifier les doublons en s’appuyant sur des mesures de similarité entre les observations. Voici son fonctionnement :
1. Calcul de la distance entre entités: Dedupe commence par mesurer la similarité entre deux lignes à l’aide de la distance affine. Ce calcul de distance pénalise plus lourdement l’ouverture d’un nouveau gap que son extension, cela rend la mesure plus robuste aux erreurs de frappe ou d’orthographe.
2. Pondération des attributs: L’utilisateur peut ensuite indiquer un coefficient sur chaque attribut afin de donner plus d’importance `a certaines informations (le nom est plus important que le prénom d’une personne pour l’identifier).
3. Régression logistique: Dedupe utilise une régression logistique pour estimer la probabilité associée à la distance calculée.
4. Apprentissage actif (active learning): Lorsque le modèle n’est pas certain (par exemple, une probabilité proche de 0,5), il demande à l’utilisateur de trancher. Les réponses permettent d’ajuster dynamiquement le modèle.
5. Réduction de la complexité: Dedupe ne compare pas toutes les paires possibles — ce qui serait trop coûteux — mais uniquement les paires les plus susceptibles d’être similaires.
Voici un exemple sur 3 lignes:
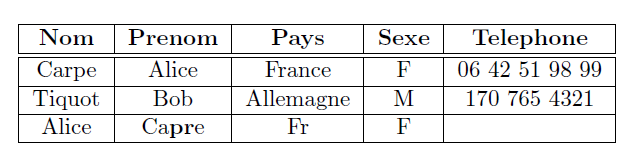
Dans cet exemple, la ligne 2 est ignorée car elle ne ressemble pas aux autres. La distance entre la ligne 1 et 3 est estimée à 35. Le modèle, déjà entraîné par régression logistique, associe cette distance à une probabilité de doublon de 0,52. Ne pouvant trancher avec certitude, il sollicite alors l’utilisateur pour étiqueter le couple.
Dans un projet de nettoyage de base client, Dedupe a permis d’identifier que “M. Jean Dupont” et “Jean-Paul Dupont” étaient probablement la même personne, malgré des différences de prénom. L’entreprise a ainsi évité d’envoyer deux fois la même offre commerciale à un client unique.
2) DeepMatcher
Alors que Dedupe repose principalement sur des distances de similarité et une régression logistique, DeepMatcher adopte une approche radicalement différente : il s’appuie sur des modèles de deep learning pour comparer les paires d’entités et apprendre à détecter les correspondances complexes, même dans des cas très ambigus. Voici les grandes étapes de son fonctionnement :
1. Encodage des attributs: Chaque champ (nom, prénom, pays, etc.) est converti en vecteurs numériques à l’aide d’un système d’embedding. DeepMatcher propose plusieurs encodeurs, notamment GloVe ou BERT.
2. Concaténation des paires: Le modèle reçoit les deux lignes à comparer, colonne par colonne. Il construit une représentation combinée de la paire, en mettant en évidence les similarités et différences sur chaque attribut.
3. Apprentissage supervisé: Deepmatcher est un modèle supervisé, le Neural Network est entraîné sur des paires ”doublon” et ”non-doublon” en essayant de généraliser sur d’autres paires.
4. Inférence: Une fois entraîné, le modèle peut estimer avec précision si deux lignes désignent la même entité, même si les données sont bruitées, partielles ou mal orthographiées.
En reprenant l’exemple précédant, le modèle va créer une représentation vectorielle de chaque attribut de :
et comprendre que

D’un côté, Dedupe se distingue par sa simplicité de mise en oeuvre et son système d’active learning, qui le rend accessible même sans grand jeu de données annoté. De l’autre, DeepMatcher, basé sur des réseaux de neurones, offre des performances impressionnantes sur des cas plus complexes, au prix d’effort de préparation des données.
Dans la suite de cet article, nous allons aborder un autre aspect essentiel du nettoyage de données : la gestion des valeurs manquantes. Comme les doublons, elles peuvent sembler anodines, mais mal traitées, elles peuvent fausser tout un pipeline d’analyse.
Des cases vides. . . mais pas sans conséquences
Dans un dataset issu d’une situation réelle, il est courant de rencontrer des valeurs manquantes. Elles peuvent être présentes en grande quantité, compromettant ainsi la profondeur des analyses et la qualité de l’entraînement des modèles. Ces absences résultent souvent d’un oubli, d’une panne, d’une erreur de
mesure ou encore d’un mauvais formatage. Le véritable défi réside dans la quantité potentielle de ces données manquantes : certains attributs peuvent être très peu renseignés. Il faut alors faire un choix stratégique.
Par exemple, dans un fichier de données de consommation énergétique, près de 20% des valeurs de température ambiante étaient manquantes en raison d’une panne temporaire du capteur.
Supprimer ces lignes aurait supprimé plusieurs jours critiques d’analyse. Une imputation contrôlée est donc nécessaire afin de conserver ces précieuses informations.
Faut-il supprimer les lignes incomplètes, au risque de perdre un % important du jeu de données ? Ou bien tenter de reconstruire ces valeurs ? Nous avons exploré des technologies basée sur l’apprentissage profond afin de compléter ces cases absentes.
1) Generative Adversarial Networks (GAN)
Pour reconstituer des données manquantes, il existe une méthode innovante et puissante : GAIN, pour Generative Adversarial Imputation Nets. Cette technique, inspirée des GAN, transforme l’imputation en une compétition entre deux réseaux de neurones. Le principe :
• Un Générateur: Il tente de remplir les cases vides avec des valeurs réalistes.
• Un Discriminateur: Il essaie de deviner, pour chaque case du dataset si la valeur est générée ou réelle.
A chaque itération, le générateur améliore ses propositions pour tromper son opposant, tandis que le
discriminateur affine sa capacité à détecter les fausses valeurs.
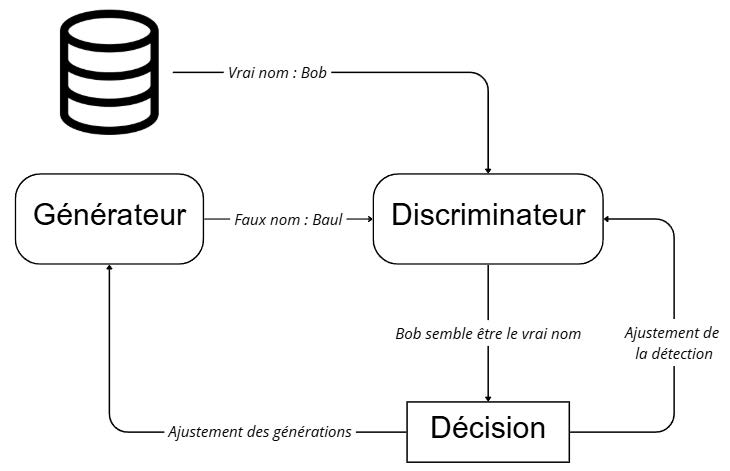
Le générateur essaie de remplir un attribut manquant nom par ’Baul’. Le discriminateur doit trouver quel est le nom réel dans la pair Baul, Bob. La décision est utilisée pour ajuster les poids des deux modèles.
2) Denoising AutoEncoder (DAE)
Semblable à son homologue AutoEncoder classique, un Denoising AutoEncoder (DAE) introduit volontairement du bruit dans les données en entrée, dans le but d’apprendre à reconstruire sa version “propre”. C’est sur ce principe que repose MIDA (Multiple Imputation using Denoising Autoencoders), un algorithme d’imputation basé sur les DAE. Son avantage principal par rapport à d’autres méthodes réside dans sa capacité à capturer et modéliser l’incertitude liée aux valeurs manquantes. MIDA ne produit pas une unique estimation, mais génère plusieurs versions imputées d’un même dataset — en injectant un bruit aléatoire différent à chaque exécution. Ces différentes versions peuvent :
• être utilisées séparément pour créer plusieurs scénarios d’analyse,
• ou fusionnées en un seul dataset via une moyenne des imputations,
• ou encore exploitées pour calculer une incertitude (par exemple via l’écart-type entre imputations).
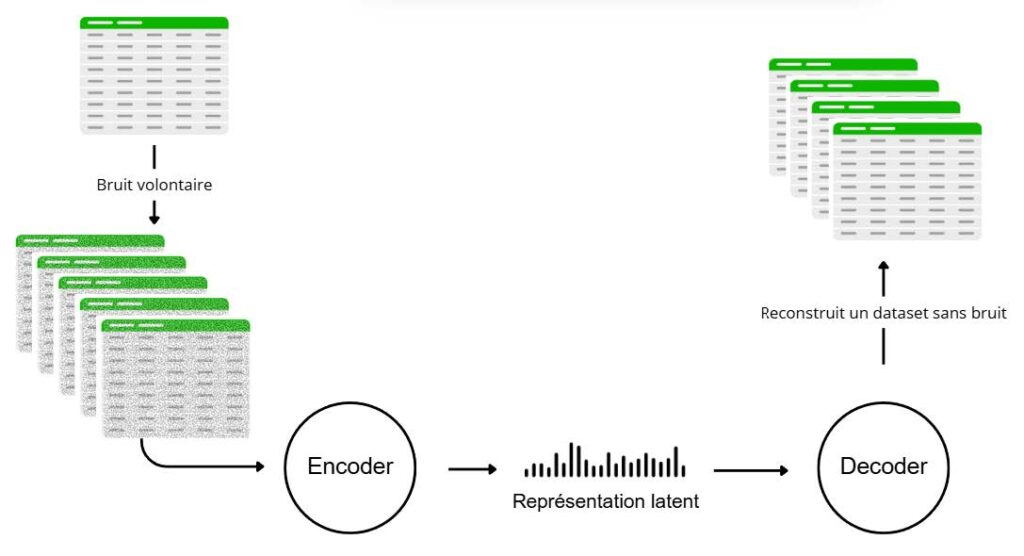
Un masque est appliqué au dataset pour simuler des perturbations. L’encodeur apprend une représentation latente de ces données bruitées, tandis que le décodeur tente de reconstruire les valeurs initiales. Le modèle apprend ainsi à corriger les valeurs manquantes.
3) Variational AutoEncoder (VAE)
HI-VAE (Heterogeneous-Incomplete Variational AutoEncoder) est une extension du Variational AutoEncoder
(VAE), conçue spécifiquement pour gérer les jeux de données comportant des types de variables hétérogènes. Contrairement à d’autres modèles qui exigent un pré-traitement lourd pour transformer toutes les colonnes dans un format unifié, HI-VAE traite chaque type de variable avec un module spécifique :
• les variables numériques sont modélisées par des distributions gaussiennes,
• les variables catégorielles par des distributions discrètes (softmax),
• et les valeurs manquantes sont directement prises en compte dans le processus de génération.
Cette technologie est un bon compromis entre performance global et précision par colonne. De plus, de part sa structure il n’exige aucun pré-traitement des données.
Les intrus du dataset : comment les détecter ?
Dans tout jeu de données réel, certaines observations semblent sortir du lot. Ces valeurs, que l’on appelle anomalies ou outliers, peuvent refléter des évènements exceptionnels, des erreurs de saisie ou des cas marginaux. Bien que rares, elles ont un impact disproportionné sur les analyses statistiques et l’apprentissage automatique.
Un simple outlier peut fausser une moyenne, biaiser un modèle ou générer des prédictions absurdes. La détection d’anomalies est donc une étape cruciale du nettoyage de données. Nous avons explorer différents algorithmes de detection d’outlier (valeur aberrante) se basant sur des technologies variées.
1) Reinforcement Learning
La détection d’anomalies est traditionnellement abordée par des méthodes statistiques, des modèles de distance ou probabilistes. Mais un autre paradigme, moins conventionnel, commence à émerger : le reinforcement learning.
Dans ce cadre, l’idée n’est plus de prédire directement si une observation est normale ou non, mais d’entraîner un agent à explorer le dataset en recevant des récompenses ou punitions selon sa capacité à détecter efficacement des outliers.
L’avantage d’utiliser cette technologie pour la détection d’anomalies réside dans sa remarquable capacité d’adaptation à des données en temps réel. Peu importe le type ou la structure du dataset, l’agent ajuste dynamiquement sa stratégie selon les retours reçus. Afin de tester cette approche, nous avons entraîné un Deep Q-Learning Agent (DQN) sur un jeu de données bancaires contenant des transactions frauduleuses. La spécificité d’un DQN réside dans son choix d’action optimal, un réseaux de neurones est entraîné afin d’établir un ensemble d’actions optimales. A chaque étape, l’agent explore ou exploite pour décider si une transaction
semble normale ou frauduleuse. Lorsqu’il identifie correctement une fraude, il reçoit une récompense positive, et une pénalité dans le cas contraire.
Grâce à ce mécanisme, l’agent apprend progressivement à reconnaître les motifs caractéristiques des fraudes, même si elles sont rares et dissimulées dans un flot de transactions normales.
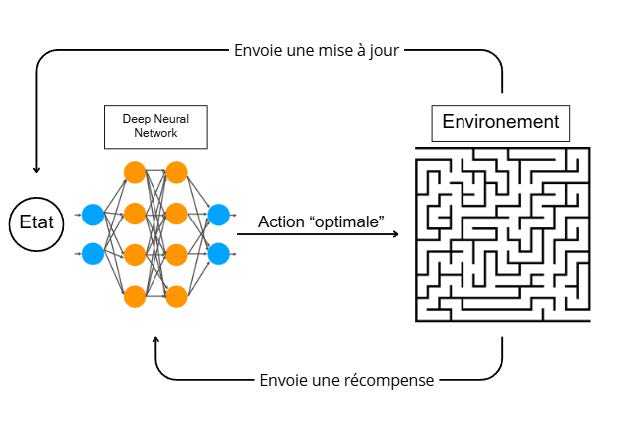
Dans un DQN, l’agent traditionnel est remplacé par un réseau de neurones. Il apprend à approximer la fonction de valeur, guidant l’agent dans la prise de décision. L’environnement fournit des états et des récompenses, permettant au modèle d’ajuster sa politique d’action.
2) AutoEncoder
De par sa structure et son mode de fonctionnement, l’AutoEncoder est un candidat idéal pour la détection d’anomalies. Il est composé de deux modules principaux :
• Un encodeur qui apprend à projeter les données d’entrée dans un espace de représentation compressé.
• Un décodeur qui tente de reconstruire les données originales à partir de cette représentation.
L’AutoEncoder est entraîné sur des données considérées comme normales. Il apprend alors à encoder les motifs récurrents et à les reconstruire avec une faible erreur. Lorsqu’une observation inhabituelle (ou bruitée) est introduite en entrée, l’encodeur ne parvient pas à en produire une représentation fidèle, et le décodeur échoue à la reconstruire correctement. Ce phénomène se traduit par une erreur de reconstruction plus élevée pour les anomalies, ce qui en fait un critère pertinent pour leur détection.
En définissant un seuil sur cette erreur, il devient possible de discriminer les données normales des
observations suspectes.
L’encoder reçoit un numéro de téléphone erroné et fabrique une représentation imprécise. Le decoder recevant cette représentation ne peux pas reconstruire efficacement l’information.
3) La sélection de modèle
Malgré le développement constant de technologies robustes et performantes, chaque algorithme présente des forces et des faiblesses propres. Face à la diversité quasi infinie des jeux de données – en structure, bruit, volume, ou distribution – aucun modèle ne peut prétendre être universellement optimal.
Ainsi, la question de la sélection du modèle adapté aux données disponibles est devenue un enjeu central en science des données. La communauté de recherche s’est notamment intéressée à des approches qui analysent les caractéristiques d’un dataset pour recommander les algorithmes les plus pertinents. Ces méthodes s’appuient souvent sur :
• Des meta-features : nombre de variables, taux de valeurs manquantes, dispersion, type de données. . .
• Des calculs de distribution statistiques : coefficient de corrélation, kurtosis, sknewness…
• Des benchmarks des jeux de données similaires
Le but est d’adapter son mode de fonctionnement selon ces attributs afin de sélectionner le potentiel meilleur modèle. Ainsi, contourner le problème de robustesse des modèles devient possible. D’autres axes sont envisageable comme des techniques d’ensembles combinant la puissance de modèle différent selon des règles définies.
Conclusion
Nettoyer les données n’est pas une simple étape préliminaire : c’est un véritable défi technique et scientifique, qui conditionne la qualité de toute analyse ou modélisation à venir.
A travers cet article, nous avons exploré un large éventail de solutions pour des problèmes clés de pré-traitement – détection de doublons, imputation de valeurs manquantes, gestion des anomalies….
Nous avons vu que l’intelligence artificielle peut aussi jouer un rôle clé dans le pré-traitement, en apprenant à reconstruire, trier, ou lire des données brutes avec une finesse inédite. Enfin, la question de la sélection de modèle rappelle qu’il n’existe pas de solution unique.
La robustesse d’un pipeline de traitement réside dans l’adaptation à la nature spécifique de chaque jeu de données, en combinant intuition humaine, expertise informatique et outils automatisés, c’est aujourd’hui une partie intégrante du développement.
Références
– Data cleaning survey and challenges – improving outlier detection algorithm in machine learning
|
– MIDA: Multiple Imputation using Denoising Autoencoders
|
