

")
[Résumé] Cet article explore et compare plusieurs méthodes d’explicabilité (LIME, SHAP, gradients, Integrated Gradients…) appliquées à des modèles de génération de texte. À travers des métriques objectives et un cadre expérimental rigoureux, nous identifions les forces, limites et compromis de chaque approche pour mieux comprendre ce qui influence réellement les réponses d’une IA.
Aujourd’hui, l’intelligence artificielle est partout : elle aide à rédiger des textes, recommander des vidéos, diagnostiquer des maladies, ou encore répondre à des questions complexes. Mais face à ces modèles d’IA puissants, une question revient souvent : comment prennent-ils leurs décisions ?
C’est tout l’enjeu de l’explicabilité de l’IA (XAI), qui vise à rendre transparents les mécanismes internes de ces modèles. Comprendre pourquoi une IA répond d’une certaine façon n’est pas seulement un défi technique, mais aussi un impératif éthique, juridique et sociétal.
Dans ce projet, nous avons comparé plusieurs méthodes dites explainers, qui mettent en lumière les éléments de l’entrée ayant le plus influencé la réponse du modèle. Notre objectif : évaluer leur pertinence, leur robustesse et leur utilité pour mieux interpréter les réponses générées par des modèles de langage. C’est pourquoi nous avons utilisé plusieurs métriques d’évaluation, afin de comparer objectivement la qualité des explications produites par chaque méthode.
C’est quoi un bon explainer ?
Un “explainer”, ou méthode d’explication, est un outil qui cherche à attribuer une sorte de “score d’importance” aux différentes parties de l’entrée d’un modèle. Par exemple, il peut dire : “le mot ‘bleu’ a beaucoup compté dans la décision du modèle, tandis que ‘conteneur’ a eu peu d’impact.”
Mais pour qu’un explainer soit vraiment utile, il ne suffit pas qu’il génère une jolie visualisation. Un bon explainer, c’est celui qui répond à plusieurs critères :
1. Fidélité : L’explication doit refléter fidèlement le raisonnement réel du modèle. Si on retire les mots que l’explainer juge les plus importants, la sortie du modèle doit changer de manière significative (comprehensiveness). À l’inverse, si on garde seulement ces mots, le modèle devrait encore produire une réponse correcte (sufficiency).
2. Stabilité et robustesse : Deux entrées presque identiques devraient donner des explications similaires. Sinon, l’explication devient difficilement exploitable.
3. Interprétabilité humaine : L’explication doit être compréhensible pour un humain. Par exemple, attribuer une importance à des “tokens” (unités internes du modèle) est inutile si on ne les relie pas à des mots réels.
4. Temps de calcul raisonnable : Certaines méthodes comme LIME sont très coûteuses à exécuter. Si une explication prend plusieurs minutes à générer, cela limite son usage pratique.
5. Adaptabilité au type de tâche : Expliquer une classification (ex. : spam ou non spam) est très différent d’expliquer une génération de texte. Les bons explainers doivent être adaptés au contexte.
C’est exactement cette problématique que nous avons explorée dans notre travail. Nous avons adapté plusieurs explainers à un cas d’usage spécifique : la génération de réponses courtes à partir de questions ouvertes, avec des modèles de type LLaMA (Meta) ou Granite (IBM).
Notre approche repose sur une idée simple mais puissante : forcer le modèle à générer une seule unité (souvent un mot), ce qui permet d’analyser très précisément quelles parties de l’entrée ont mené à cette sortie. En travaillant sur cette granularité fine, on peut comparer de manière équitable les différentes méthodes d’explication.
Méthodes testées
Imaginez : vous fournissez un contexte (un texte, un extrait de document) et vous posez une question à une intelligence artificielle. Elle vous donne une réponse… mais comment savoir sur quoi elle s’est appuyée ?
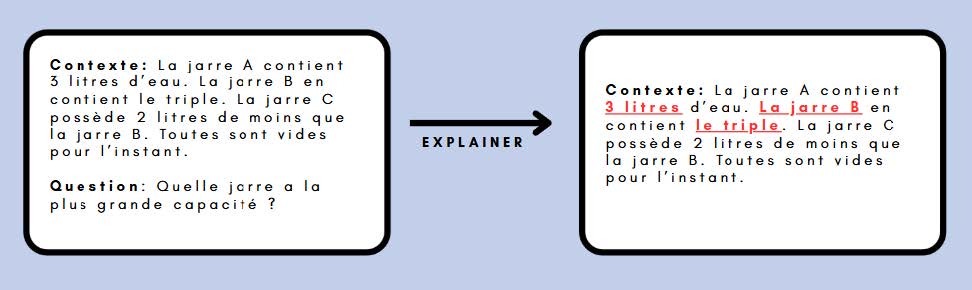
Pour cela, nous avons testé plusieurs méthodes d’explication, dont :
👉 LIME, SHAP, Gradient, Gradient × Input, Integrated Gradients, et LRP.
Prenons un exemple simple: voici le contexte : “Marie Curie est une physicienne polonaise naturalisée française. Elle a reçu deux prix Nobel.”
Question :
“Combien de prix Nobel Marie Curie a-t-elle reçus ?”
Réponse générée par l’IA :
“Elle a reçu deux prix Nobel.”
Nous allons voir comment expliquer cette réponse grâce aux différentes méthodes.
LIME
Compréhension par perturbation locale : LIME crée de multiples versions altérées du contexte d’entrée (en masquant ou supprimant des mots), puis entraîne un modèle simple pour approximer localement le comportement du modèle génératif.
Exemple : On génère plusieurs contextes sans “deux prix Nobel” → la réponse devient floue ?
➡️ LIME attribue alors une importance forte à “deux prix Nobel”.
Avantage : Intuitif et capable de s’adapter à n’importe quel modèle de Machine Learning.
Limite : Peu robuste avec des entrées longues ou fortement contextuelles.
SHAP
Attribution coopérative de la sortie : SHAP estime la contribution marginale de chaque mot en testant toutes les combinaisons possibles (approximées) et en s’appuyant sur la théorie des jeux de Shapley. SHAP étudie les dépendances partielles entre tous les tokens.
Exemple : Contributions calculées : “deux” → +0.6 “prix Nobel” → +0.3 “Marie Curie” → +0.1
Avantage : Méthode rigoureuse, fondée sur une base mathématique solide.
Limite : Très coûteux en calcul, surtout avec des textes longs.
Gradient
Analyse de la sensibilité du modèle On calcule le gradient de la sortie par rapport aux embeddings des mots : un fort gradient indique qu’une petite modification du mot change significativement la sortie.
● Gradient simple : dérivée brute de la sortie par rapport à chaque mot.
● Gradient × Input : pondère ce gradient par l’activation du mot d’entrée.
Exemple : Le mot “deux” → fort gradient = influence élevée sur la prédiction.
Avantage : Très rapide à exécuter.
Limite : Moins fiable si le modèle est très non-linéaire ou ambigu.
Integrated Gradients
Attribution par intégration. On intègre les gradients le long d’un chemin allant d’un contexte neutre à l’entrée réelle, capturant ainsi l’effet cumulatif de chaque mot.
Exemple : En passant progressivement d’un contexte vide à “Elle a reçu deux prix Nobel”, on observe que “deux” et “prix Nobel” sont les premiers à activer la réponse correcte.
Avantage : Fournit une attribution fidèle et théoriquement fondée.
Limite : Nécessite de bien choisir le “baseline” (contexte de référence).
LRP
Propagation de la pertinence couche par couche. LRP redistribue rétroactivement la sortie générée à travers les couches du réseau jusqu’aux entrées, en suivant les poids d’activation pour quantifier la contribution de chaque token.
Exemple : Réponse : “Elle a reçu deux prix Nobel” → Attribution : “deux” → 55% “prix Nobel” → 35% “reçu” → 10%
Avantage : Très bien adapté aux modèles de génération auto-régressive comme GPT.
Limite : Implémentation technique complexe, dépendante de l’architecture interne.
Comment juger si une explication est bonne ?
Évaluer une explication, ce n’est pas aussi simple que de dire « ça a l’air logique ». Une bonne explication doit aider à comprendre les décisions du modèle… mais encore faut-il savoir comment mesurer cette utilité.
Pour cela, on utilise ce qu’on appelle des métriques d’évaluation, qui permettent de comparer objectivement la qualité des explications produites. Une métrique, c’est un outil de mesure : elle permet de quantifier un aspect précis du comportement d’un modèle ou d’une explication, pour pouvoir comparer, évaluer ou améliorer les résultats de façon objective.
Dans notre projet, nous avons utilisé trois métriques pour comparer la qualité des explainers, c’est-à-dire les méthodes qui génèrent des explications :
AOPC Comprehensiveness : Cette métrique évalue dans quelle mesure la confiance du modèle diminue lorsque les mots identifiés comme les plus importants par l’explainer sont supprimés. L’idée est la suivante : si ces mots sont vraiment essentiels à la prédiction, leur suppression doit faire chuter la confiance du modèle. Une valeur élevée signifie donc que l’explication identifie bien les éléments critiques.
AOPC Sufficiency : À l’inverse, cette métrique évalue si les mots conservés, jugés importants par l’explainer, suffisent à maintenir la prédiction du modèle. Si la confiance reste haute avec seulement ces mots, cela montre que l’explication isole efficacement l’information clé. Ici, une valeur basse est souhaitable.
Kendall Tau : C’est un coefficient statistique qui compare deux classements : celui des mots importants fourni par l’explainer, et un classement de référence. Ce dernier est construit en mesurant l’impact réel de chaque mot sur la prédiction, en les retirant un par un (méthode leave-one-out). Le coefficient varie de –1 (classements inversés) à 1 (classements identiques). Plus il est proche de 1, plus l’explainer produit un classement fidèle.
Cadre expérimental et protocole de test
Nous évaluons à présent les méthodes d’explicabilité introduites dans une des sections précédentes — LIME, SHAP, Gradient, Gradient × Input et Integrated Gradient — à l’aide des trois métriques que l’on vient de voir :
● AOPC Comprehensiveness (plus la valeur est haute, mieux c’est)
● AOPC Sufficiency (plus la valeur est basse, mieux c’est)
● Kendall tau (plus la valeur est haute, mieux c’est)
L’image ci-dessous illustre le déroulement de cette évaluation. Pour chaque exemple, un contexte c’est-à-dire un extrait de texte contenant les informations nécessaires et une question portant sur ce contenu sont fournis au modèle. Le modèle génère alors une réponse censée être fondée sur le contexte. L’explainer que l’on souhaite évaluer est ensuite appliqué pour identifier les éléments du contexte ou de la question qui ont le plus influencé cette réponse. Enfin, les métriques d’évaluation sont calculées afin de mesurer la pertinence de l’explication produite par cet explainer.
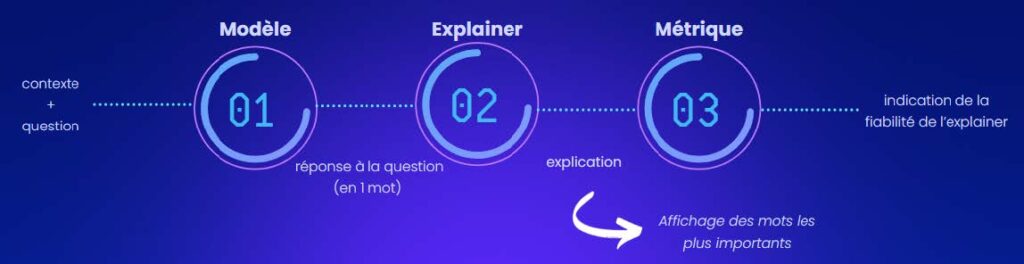
Chaque explainer a été appliqué à 500 exemples de question answering, et évalué sur trois modèles de génération de texte : Granite 2B, LLaMA 1B et LLaMA 3B.
Nous indiquons également le temps moyen d’exécution par exemple pour chaque méthode.
Enfin, nous incluons une baseline d’explainer aléatoire, qui attribue des scores d’importance de manière aléatoire, afin de servir de point de comparaison pour évaluer l’efficacité des autres explainers.
Résultats et enseignements
Pour visualiser les performances des différents explainers sur le modèle Granite 2B, nous avons utilisé des histogrammes. Chaque graphique correspond à une métrique : AOPC Comprehensiveness, AOPC Sufficiency ou Kendall Tau. Chaque barre représente un explainer.
Ce choix permet de voir rapidement l’écart entre l’explainer aléatoire et les autres explainers. Il montre efficacement que tous les explainers testés font mieux que la ligne de base aléatoire, et ce pour toutes les métriques.
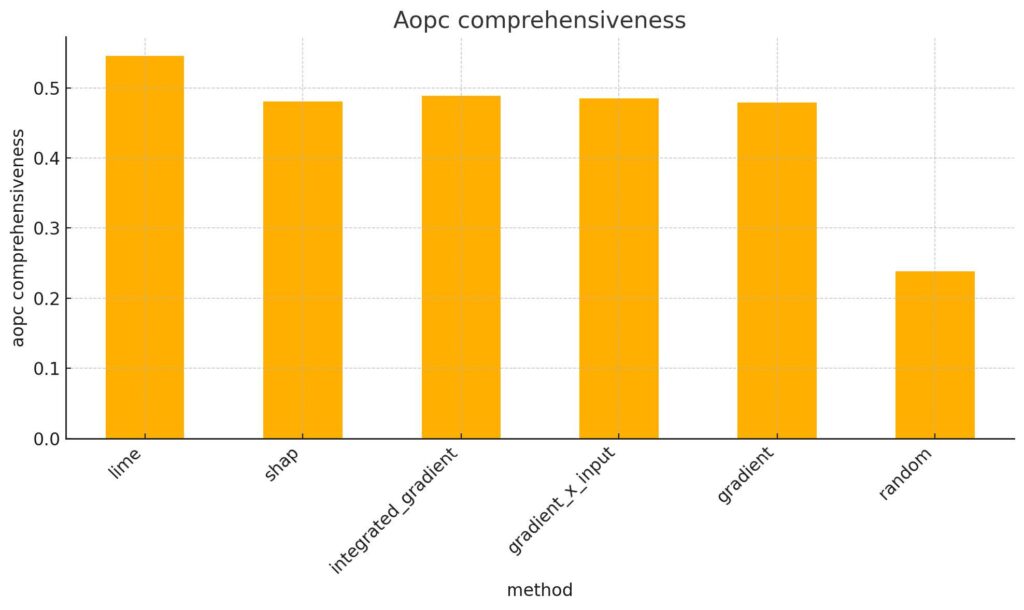
Comme le montre le premier histogramme, l’explainer aléatoire obtient un score AOPC Comprehensiveness bien plus faible (0,24) que les autres méthodes, qui dépassent toutes 0,47.
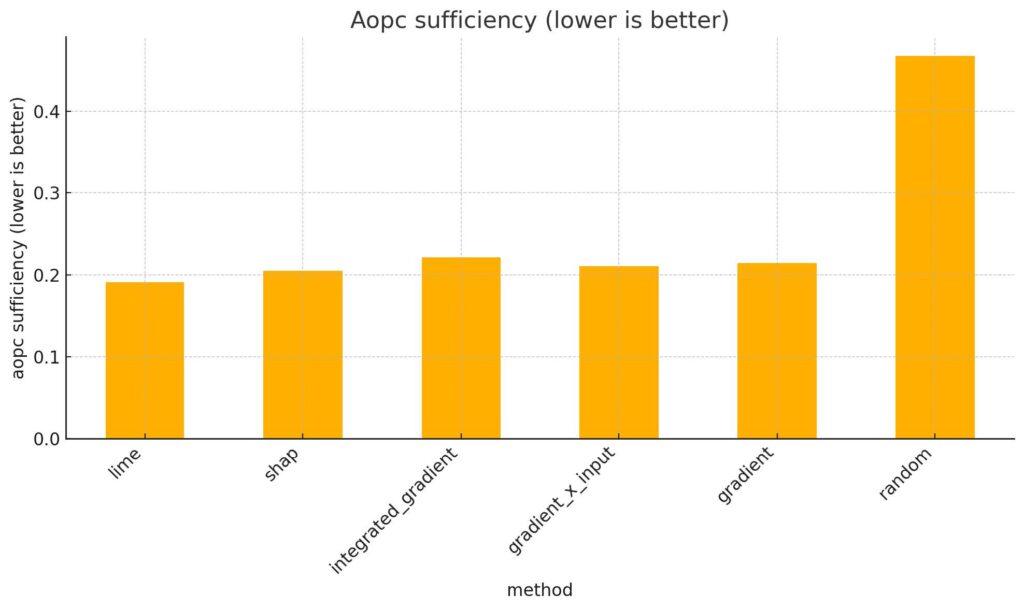
Sur ce deuxième graphique, on voit que l’explainer aléatoire a un score plus haut (0,47) que les autres (entre 0,19 et 0,22). Cela veut dire que les mots choisis au hasard gardent moins bien la prédiction du modèle. Les mots choisis par les vrais explainers sont donc plus utiles.
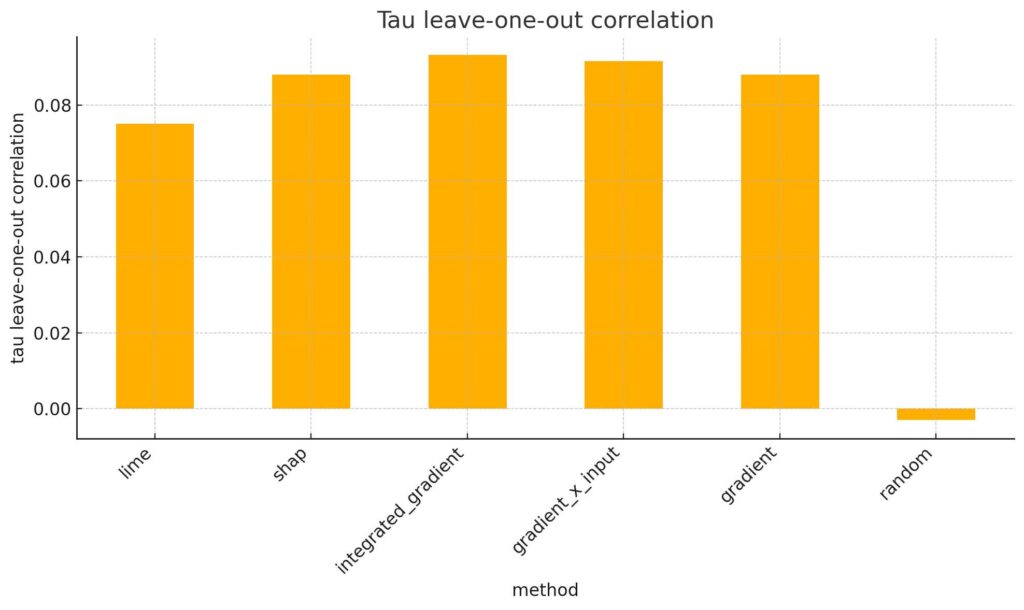
Le troisième graphique montre encore mieux la différence : l’explainer aléatoire a un score Kendall Tau un peu négatif (–0,003), alors que les autres méthodes ont des scores positifs entre 0,075 et 0,093.
Ces scores restent bas, nous aimerions avoir des valeurs proches de 1, mais ils montrent quand même que les explainers testés font mieux que l’explainer aléatoire.
Cela veut dire que ces méthodes reflètent mieux l’ordre d’importance des mots selon le modèle.
Les graphiques en barres montrent bien la différence de performance entre les explainers testés et l’aléatoire.
Mais ils ne permettent pas de comparer précisément les explainers entre eux.
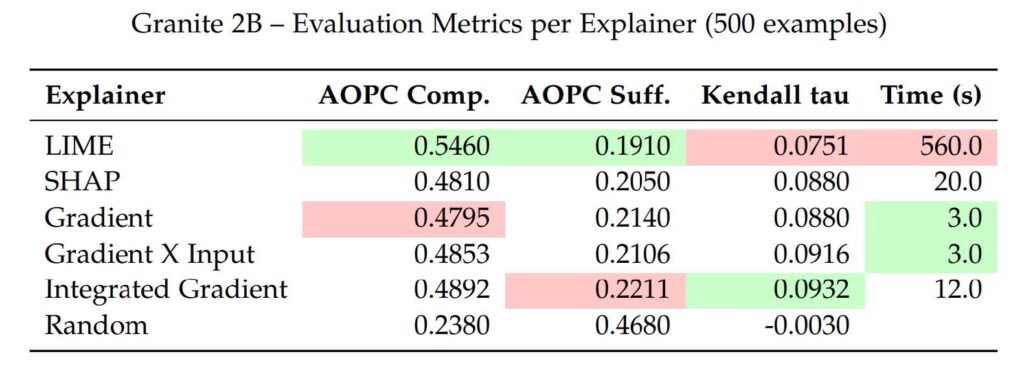
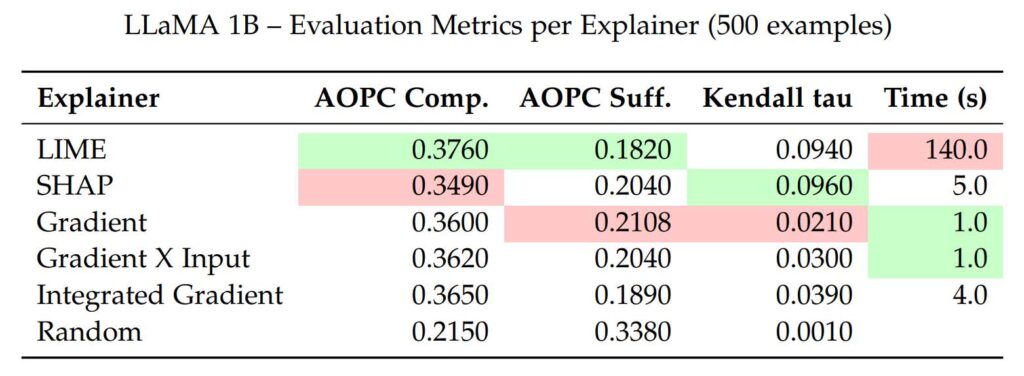
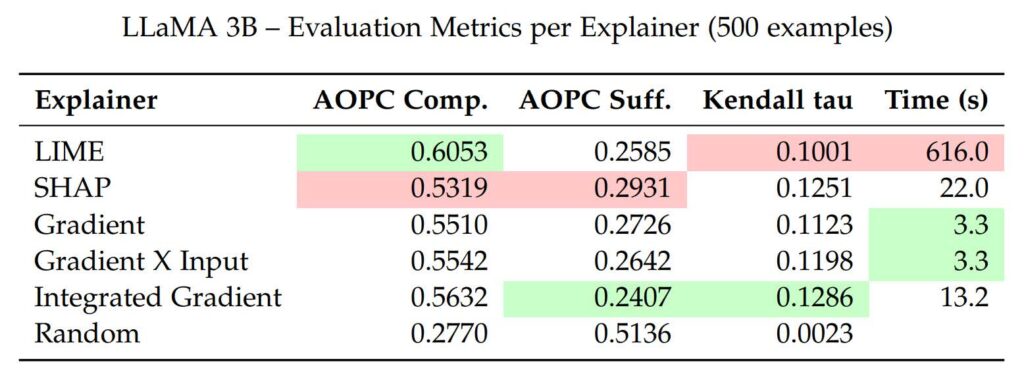
Pour mieux comparer, nous présentons des tableaux avec les valeurs exactes des métriques pour chaque explainer et pour les trois modèles : Granite 2B, LLaMA 1B, et LLaMA 3B.
Les meilleurs scores sont en vert, les moins bons en rouge, pour aider à la lecture.
Les résultats varient selon les trois modèles.
Mais comparer les scores d’explicabilité entre modèles n’est pas forcément pertinent.
En effet, les métriques d’évaluation, surtout Kendall tau, semblent sensibles à la complexité du modèle.
Par exemple, les valeurs de Kendall tau restent globalement faibles et dépassent 0,10 seulement avec le modèle LLaMA 3B, qui est aussi le plus complexe utilisé.
Avec cela en tête, nous nous concentrons maintenant sur la performance relative des explainers au sein de chaque modèle.
AOPC Comprehensiveness
Sur tous les modèles, LIME et Integrated Gradient obtiennent les meilleurs scores de comprehensiveness. Par exemple, sur Granite 2B, LIME atteint 0.5460 et Integrated Gradient 0.4892, contre 0.2380 pour l’explainer aléatoire. Sur LLaMA 3B, leurs scores montent à 0.6053 et 0.5632, ce qui montre leur efficacité même sur des modèles complexes.
Les méthodes Gradient et Gradient × Input sont un peu moins bonnes, mais restent proches. Sur Granite 2B : 0.4795 et 0.4853. Sur LLaMA 3B : 0.5510 et 0.5542.
SHAP a des scores plus faibles : 0.4810 (Granite 2B) et 0.5319 (LLaMA 3B), mais reste au-dessus de l’aléatoire, et proche des méthodes à base de gradient.
AOPC Sufficiency
Sur Granite 2B, LIME obtient le meilleur score (0.1910), montrant qu’il isole bien les mots pertinents. Il reste en tête sur LLaMA 1B (0.1820), mais devient moins dominant sur LLaMA 3B (0.2585), probablement à cause de la complexité du modèle.
Integrated Gradient est le moins bon sur Granite 2B (0.2211), mais parmi les meilleurs sur LLaMA 1B (0.1890) et LLaMA 3B (0.2407), grâce à sa robustesse.
Gradient et Gradient X Input ont des performances très proches. Gradient X Input fait légèrement mieux, surtout sur LLaMA 3B (0.2642 vs. 0.2726).
SHAP a des scores corrects sur Granite 2B (0.2050) et LLaMA 1B (0.2040), mais chute sur LLaMA 3B (0.2931), probablement à cause de la complexité du modèle.
L’explainer aléatoire reste toujours le pire (jusqu’à 0.5136), ce qui confirme la pertinence des autres méthodes.
Kendall Tau
Les scores de Kendall Tau sont globalement faibles, ce qui peut surprendre. Cela vient probablement du classement de référence utilisé : la méthode leave-one-out (LOO) ne mesure que l’impact individuel des mots, sans tenir compte des interactions entre eux. Cela limite la fidélité du classement obtenu.
On remarque aussi que les scores de Kendall Tau augmentent légèrement avec la taille du modèle. LLaMA 3B, plus complexe, obtient de meilleurs résultats que Granite 2B ou LLaMA 1B. Ces observations mériteraient d’être étudiées plus en détail.
Malgré des valeurs modestes, tous les explainers font mieux que l’explainer aléatoire (ex. : –0.0030 pour Granite 2B). Integrated Gradient et Gradient X Input atteignent par exemple 0.0932 et 0.0916. Sur LLaMA 3B, SHAP et Integrated Gradient dépassent 0.12. Cela montre que les explainers capturent des signaux pertinents.
Integrated Gradient est l’explainer le plus performant sur Granite 2B et LLaMA 3B. Les approches Gradient, Gradient X Input et SHAP suivent, avec des scores autour de 0.08–0.12. LIME est un peu en dessous, ce qui peut s’expliquer par la variabilité de son approche.
Le comportement change pour LLaMA 1B. LIME et SHAP obtiennent les meilleurs résultats (environ 0.09), tandis que Gradient et Gradient × Input chutent à 0.02–0.03. Cela pourrait être dû à la capacité plus faible du modèle, qui rend les gradients moins informatifs.
Temps de calcul
Le coût de calcul varie beaucoup selon les explainers et les modèles.
LIME est le plus lent : 560 secondes sur Granite 2B, 616 sur LLaMA 3B (10 % de plus). Sa méthode d’échantillonnage locale le rend lent, surtout pour les grands modèles.
Les méthodes basées sur les gradients (Gradient et Gradient × Input) sont très rapides : environ 3 secondes.
Integrated Gradient est plus lent (12 à 13 secondes) car il calcule plusieurs gradients, mais reste raisonnable.
SHAP est un compromis, avec 20 à 22 secondes d’exécution.
Ces différences sont importantes pour choisir un explainer adapté aux modèles lourds ou aux gros jeux de données.
Récapitulatif des résultats
LIME et Integrated Gradient obtiennent les meilleures performances sur les trois métriques. Leur classement peut varier un peu selon le modèle ou la métrique, mais ils occupent souvent les premières places. Gradient et Gradient × Input suivent de près, avec des résultats très proches. Gradient × Input dépasse légèrement Gradient sur tous les modèles et métriques. SHAP est plus variable : il peut rivaliser avec les méthodes basées sur les gradients, mais son classement dépend du modèle et de la métrique. Il reste toutefois en dessous de LIME et Integrated Gradient.
Côté temps d’exécution, Gradient et Gradient × Input sont les plus rapides, suivis d’Integrated Gradient, qui reste raisonnable malgré un coût plus élevé. SHAP est plus lent, mais utilisable. LIME est beaucoup plus lent que les autres, ce qui peut limiter son usage pour de grands modèles ou de gros volumes.
Au final, Integrated Gradient offre le meilleur compromis entre performance et temps d’exécution.
Conclusion
Notre exploration des méthodes d’explicabilité montre que rendre l’IA plus lisible est un défi technique complexe, mais indispensable. Si des outils comme Integrated Gradients ou LIME permettent déjà d’éclairer partiellement les décisions des modèles, aucun explainer n’est universel : chacun présente des compromis entre précision, temps de calcul et adaptabilité.
Cette diversité d’approches rappelle qu’il n’existe pas une seule façon de “bien expliquer” une IA. L’efficacité d’un explainer dépend toujours du contexte, de la tâche, du type de modèle… mais aussi des attentes des utilisateurs — chercheurs, décideurs, ou grand public.
À ce titre, l’explicabilité ne peut rester cantonnée à un outil de recherche : elle doit devenir un composant de conception intégré dans le développement des systèmes d’IA.
À l’avenir, l’un des grands enjeux sera de concevoir des explications plus interactives, multimodales et adaptées à l’humain, capables de rendre compte des raisonnements profonds des modèles tout en restant compréhensibles. Car la véritable puissance de l’IA ne réside pas uniquement dans ce qu’elle peut faire, mais dans ce que nous sommes capables de comprendre, de questionner et de maîtriser.
Pour en savoir plus :
Pour les novices / tout public :
Sur l’explicabilité des IA : Explainable AI (XAI) : comprendre les décisions de l’IA – IONOS
Sur l’explicabilité des IA et certains explainers (LIME et SHAP) : Explainable AI, LIME & SHAP for Model Interpretability | Unlocking AI’s Decision-Making | DataCamp
Sur Kendall Tau : https://datatab.fr/tutorial/kendalls-tau
Pour les expérimentés / approfondissement :
Sur l’explicabilité des IA : https://explainer.ai/
Sur certains explainers (LIME et SHAP) : https://arxiv.org/html/2305.02012v3
Sur les métriques AOPC Comprehensiveness et AOPC Sufficiency : 2408.08137
Sur la métrique Kendall Tau : Understanding Kendall’s Tau Rank Correlation | by Data Science & Beyond | Medium
