

[Résumé] Le projet ITEM explore une nouvelle forme de création artistique assistée par intelligence artificielle : transformer automatiquement l’émotion d’une image en musique. En combinant vision par ordinateur, modélisation émotionnelle et génération musicale, ce système analyse le contenu émotionnel d’une image puis génère une composition cohérente avec l’ambiance perçue. Cet article présente l’architecture du système, les défis techniques rencontrés et les perspectives offertes par cette approche.
La génération automatique de musique à partir d’images représente un défi fascinant à l’intersection de l’intelligence artificielle, de la vision par ordinateur et de la musicologie computationnelle. Le projet ITEM (Image to Emotional Music) propose une approche innovante pour créer de la musique basée sur les émotions véhiculées par une image donnée. Cette technologie ouvre des perspectives nouvelles pour la création artistique et l’accompagnement multimédia.
Cet article présente une explication de la méthodologie développée afin d’analyser l’émotion d’une image pour l’utiliser dans la génération d’une musique. Nous explorerons les défis techniques rencontrés, les solutions innovantes apportées et les résultats obtenus.
Fondements théoriques et objectifs du projet
Contexte scientifique et motivation
La relation entre émotion visuelle et expression musicale constitue un domaine de recherche multidisciplinaire établi depuis plusieurs décennies. Les travaux pionniers en psychologie cognitive ont démontré que les humains associent naturellement certains états émotionnels spécifiques à des couleurs, des formes ou encore des musiques. Cette correspondance émotionnelle entre perception visuelle et auditive forme la base théorique du projet ITEM.
L’analyse émotionnelle s’appuie sur deux dimensions fondamentales. La valence mesure si une émotion est positive (joie, satisfaction) ou négative (tristesse, colère). L’arousal correspond à l’intensité d’activation, allant du calme (relaxation, sérénité) à l’excitation (stress, euphorie). Ensemble, ces deux axes permettent de localiser précisément chaque émotion : la joie combine valence positive et arousal élevé, tandis que la mélancolie associe valence négative et arousal faible. Ce modèle bidimensionnel fournit un cadre quantitatif pour analyser les émotions visuelles et les traduire en paramètres musicaux.
L’objectif principal consiste à développer un système capable de traduire automatiquement le contenu émotionnel d’une image en une composition musicale cohérente. Cette transformation s’effectue en trois étapes distinctes mais interconnectées : l’analyse émotionnelle de l’image d’entrée, la génération de la structure musicale correspondante, et l’optimisation de la performance finale.
Architecture du système proposé
Le système ITEM repose sur une architecture modulaire comprenant deux composants principaux (Figure 1) :
- EmoCLIPture : se charge de l’analyse émotionnelle des images en combinant les capacités du modèle ResNet50 pour l’analyse régionale spécifique et du modèle CLIP pour l’analyse sémantique globale.
- EmoDisGen : basé sur EmoDisEntanger[1], génère ensuite la musique correspondante en utilisant une approche en deux étapes. Tout d’abord la création d’une mélodie basée sur la valence émotionnelle (Définition : il s’agit de la mesure quantitative de notre état d’esprit positif ou négatif, soit un stimulus négatif ou positif mesuré par le sourire) puis l’ajout d’arrangements selon l’intensité émotionnelle.
Cette architecture permet une optimisation indépendante de chaque composant tout en maintenant une cohérence globale du système. L’approche adoptée s’inspire des modèles de traitement cognitif humain, où la perception émotionnelle précède et guide l’expression créative.
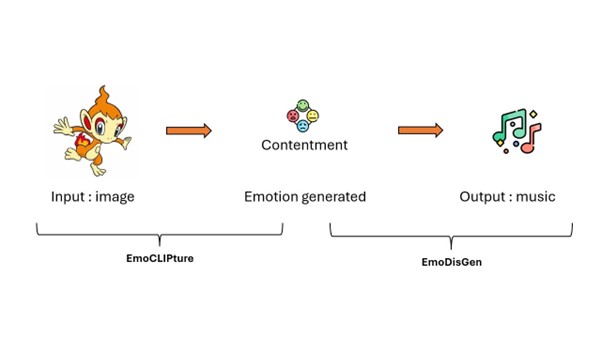
Figure 1 : Schéma détaillé de l’architecture modulaire du système ITEM
Préparation et analyse des données visuelles
Constitution et caractéristiques du dataset EmoSet
Le développement d’un système robuste d’analyse émotionnelle nécessite un dataset d’entraînement complet. Nous avons choisi d’utiliser le dataset EmoSet, comprenant 118 000 images étiquetées. Chaque image est annotée selon huit émotions principales : amusement, émerveillement, contentement, excitation, colère, dégoût, peur et tristesse (Figure 2).

Figure 2 : Répartition des émotions du dataset EmoSet
La richesse d’EmoSet réside dans son annotation multicritère. Au-delà des étiquettes émotionnelles, chaque image est caractérisée par des attributs quantitatifs comme la luminosité et la colorimétrie, des éléments contextuels incluant les objets présents (409 types d’objets possibles) et les types de scènes (254 catégories), ainsi que l’analyse des expressions faciales lorsque présentes.
Cette approche multi-attributs permet au système de comprendre non seulement l’émotion dominante d’une image, mais également les facteurs visuels sous-jacents qui contribuent à cette perception émotionnelle. Par exemple, une image étiquetée comme “contentement” pourra être associée à des valeurs élevées de luminosité, à la présence d’objets naturels comme des fleurs ou des paysages, et à des expressions faciales positives.
Pour affiner cette classification, nous avons positionné ces huit émotions selon les dimensions de valence et d’arousal (intensité) du modèle circomplexe de Russell (Figure 3). Le placement des émotions étant subjectif, nous avons réalisé un sondage au sein de l’équipe pour obtenir une valeur moyenne de valence-arousal pour chaque émotion.
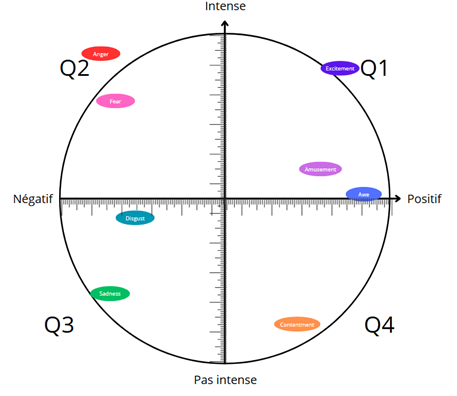
Figure 3 : Positionnement des huit émotions sur le quadrant
Méthodologie de préparation des données
La préparation des données visuelles suit un protocole rigoureux garantissant la qualité et la cohérence des annotations. Chaque image subit certaines transformations notamment une normalisation standardisée pour uniformiser les conditions d’analyse et un redimensionnement pour pouvoir les mettre en entrée des modèles.
Les annotations émotionnelles des images s’effectuent par consensus inter-annotateurs, avec un coefficient de concordance minimal requis de 0.8. Cette approche garantit la fiabilité des étiquettes émotionnelles et réduit les biais subjectifs inhérents à l’interprétation émotionnelle.
Développement d’un analyseur d’émotions visuelles avec EmoCLIPture
Architecture hybride ResNet50-CLIP
EmoCLIPture adopte une approche hybride innovante combinant les forces complémentaires de ResNet50 et CLIP (Figure 4). Cette architecture duale permet une analyse des images selon deux perspectives distinctes mais complémentaires.
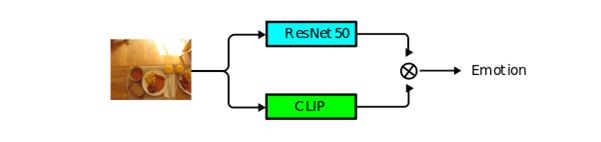
Figure 4 : Schéma de l’architecture hybride ResNet50-CLIP
ResNet50, optimisé pour l’analyse régionale spécifique, excelle dans la détection et l’analyse des éléments visuels locaux. Sa capacité à identifier les caractéristiques fines comme les textures, les formes géométriques et les détails compositionnels en fait un outil précieux pour comprendre les nuances émotionnelles véhiculées par les éléments visuels spécifiques.
CLIP, conçu pour l’analyse sémantique globale, apporte une compréhension contextuelle de l’image dans son ensemble. Son entraînement sur de nombreuses paires texte-image lui confère une capacité remarquable à saisir le sens global d’une image ainsi qu’une capacité d’analyse sur des types d’images qu’il n’a jamais vus auparavant.
Adaptations architecturales spécifiques
L’intégration de ResNet50 dans le système EmoCLIPture nécessite des modifications de son classificateur. A la base, le réseau est adapté pour prédire 1000 catégories d’image, les 1000 catégories présentes dans ImageNet. Ainsi, il a fallu modifier certaines couches pour prédire les huit catégories émotionnelles cibles en s’aidant d’attributs auxiliaires comme la luminosité et la colorimétrie.
Deux configurations de classificateur ont été testées et comparées. Le premier utilise un neurone unique pour chaque caractéristique, privilégiant la simplicité et l’efficacité computationnelle tandis que le second emploie 128 neurones par caractéristique, permettant une représentation plus riche mais au coût d’une complexité accrue.
L’intégration de YOLO (You Only Look Once) dans le pipeline d’inférence permet la détection d’objets en temps réel. YOLO prédit simultanément la localisation (avec des boites englobantes) et les classes d’objets en une seule passe à travers le réseau. Il divise l’image en grille où chaque cellule détecte directement les objets présents. Cet ajout permet au système global (Figure 5) de prendre en compte la présence de certains objets dans l’image pour orienter sa classification (ex : la détection d’un crâne pousse fortement le ResNe50 à prédire l’émotion de peur).
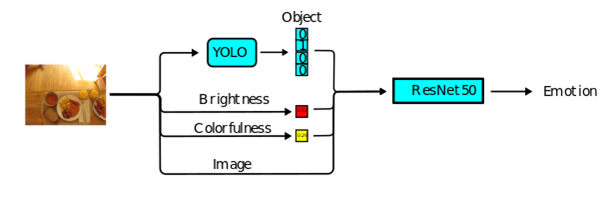
Figure 5 : Architecture de la configuration finale du ResNet50
Performances et analyse des résultats
Les résultats obtenus avec EmoCLIPture démontrent l’efficacité de l’approche hybride adoptée. L’analyse des performances révèle que certaines émotions, comme le contentement, présentent des défis particuliers en raison de leur proximité perceptuelle avec d’autres catégories comme l’amusement et l’excitation.
Cette difficulté de discrimination reflète la complexité intrinsèque de la perception émotionnelle humaine, où les frontières entre émotions proches peuvent être subjectives et contextuelles. Les erreurs de classification observées correspondent souvent à des cas où même un annotateur humain pourrait hésiter entre plusieurs catégories.
L’analyse comparative entre ResNet50 et CLIP (Figure 6) révèle leurs contributions complémentaires. ResNet50 excelle dans la reconnaissance de patterns visuels spécifiques associés à certaines émotions, tandis que CLIP apporte une compréhension contextuelle plus globale et nuancée.
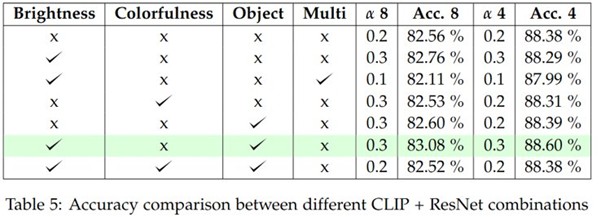
Figure 6 : Tableau de performance d’EmoCLIPture
Création d’un générateur de musique émotionnelle avec EmoDisGen
Approche compositionnelle en deux étapes
EmoDisGen reprend le projet EMO-Disentanger et implémente une stratégie de génération musicale en deux étapes distinctes, inspirée du processus créatif humain. Cette approche séquentielle permet un contrôle précis et nuancé de l’expression émotionnelle dans la composition générée.
La première étape, centrée sur la composition, génère une structure musicale fondamentale basée sur la valence émotionnelle de l’image d’entrée. Cette étape produit une partition simplifiée incluant la mélodie principale et la progression harmonique, correspondant conceptuellement à une feuille guide (ou “lead sheet”) en terminologie musicale.
La seconde étape, focalisée sur la performance, enrichit cette structure de base en ajoutant l’intensité émotionnelle correspondant au niveau d’activation (arousal) détecté. Cette phase introduit l’accompagnement, les variations rythmiques et les nuances dynamiques qui donnent vie à la composition.
Datasets musicaux et préparation
La qualité du générateur musical dépend étroitement de la richesse et de la diversité des données d’entraînement. EmoDisGen s’appuie sur une combinaison stratégique de datasets existants et nouvellement constitués, totalisant plus de 25 000 fichiers MIDI.
Les datasets originaux incluent EMOPIA (1 071 fichiers pop d’environ 35 secondes avec émotions), Pop1K7 (1 747 fichiers de pop occidentale, japonaise et coréenne d’environ 4 minutes avec émotion) et Hooktheory (18 542 fichiers de divers genres d’environ 24 secondes sans l’émotion). Ces données sont complétées par MAESTRO (1 276 fichiers classiques de 2 à 30 minutes sans l’émotion) et EIMG (3 000 fichiers classiques de 15 secondes avec émotion et valence/arousal).
Cette diversité de genres, de durées et de styles enrichit considérablement les capacités expressives du système, permettant une adaptation fine à différents contextes émotionnels et esthétiques.
Préprocessing avancé et défis techniques
Le préprocessing des données musicales représente un défi technique majeur, particulièrement pour la détection automatique des mélodies et des progressions harmoniques. La méthodologie développée s’appuie sur des heuristiques sophistiquées adaptées aux spécificités de chaque dataset.
Pour la détection mélodique, deux approches distinctes ont été développées. Pour EIMG, seule la main droite est considérée pour l’analyse de la mélodie qui dépend de plusieurs critères. Il y a l’élimination des silences supérieurs à 2 secondes, des notes dont le rythme est doublement supérieur ou plus au tempo originel, et la conservation de la séquence continue la plus longue pour chaque musique. Pour MAESTRO, la complexité et la longueur des compositions nécessitent une approche moins nuancée privilégiant uniquement la partie la plus aigüe.
La détection harmonique pose des défis encore plus complexes. L’approche initiale, basée sur la détection de notes simultanées, s’avère insuffisante avec seulement 50% de précision. L’intégration de la bibliothèque music21 et de ses fonctions de parsing et de chordification améliore significativement les résultats, atteignant 66.6% de précision pour les accords “proches” de la référence.
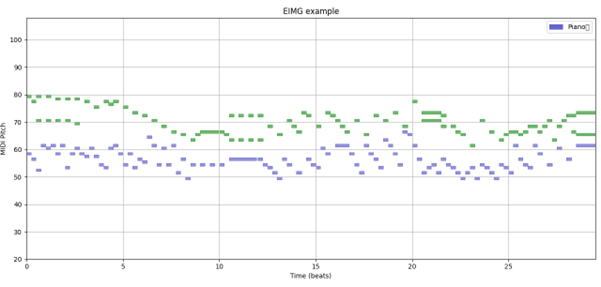
Figure 7 : Exemples de tokenisation sur EIMG
Tokenisation et représentation fonctionnelle
La tokenisation adopte une représentation fonctionnelle inspirée de REMI, enrichie de tokens spécifiques pour les émotions et les harmonies. Cette approche permet une génération musicale sensible au contexte émotionnel tout en maintenant la cohérence structurelle.
L’innovation principale réside dans la répétition du token émotionnel à intervalles réguliers (chaque mesure) pour maintenir la cohérence émotionnelle dans les séquences longues (Figure 8). Cette stratégie s’avère cruciale pour éviter la dérive émotionnelle souvent observée dans les systèmes de génération séquentielle.
La distinction entre les deux étapes de génération se reflète dans la tokenisation. L’étape 1 utilise des tokens émotionnels binaires (positif/négatif) et se concentre sur la mélodie et les métadonnées harmoniques. L’étape 2 introduit des tokens émotionnels quaternaires (Q1-Q4) et divise la séquence en parties distinctes pour la mélodie principale et l’accompagnement.
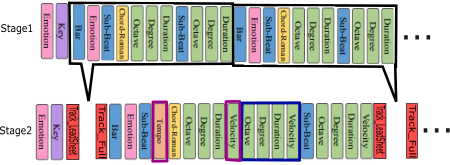
Figure 8 : Exemples de tokenisation
Résultats expérimentaux et analyse des performances
Méthodologie d’évaluation
L’évaluation des performances du système ITEM nécessite des métriques adaptées aux spécificités de la génération musicale émotionnelle. L’approche adoptée combine évaluations objectives automatisées et analyses subjectives par panels d’experts.
Les métriques objectives incluent la précision de classification émotionnelle, la cohérence harmonique des compositions générées et la diversité mélodique. Ces mesures quantitatives sont complétées par des évaluations perceptuelles humaines évaluant la correspondance entre l’émotion visuelle d’origine et l’expression musicale générée.
Résultats par dataset et configuration
Les résultats expérimentaux révèlent des performances variables selon les datasets et configurations utilisées. HookTheory, avec sa grande diversité stylistique, produit des résultats particulièrement robustes pour la génération d’étape 1. MAESTRO excelle dans la génération de compositions longues et structurellement cohérentes.
EIMG, malgré sa taille plus réduite, apporte une contribution significative lorsqu’utilisé en fine-tuning sur des modèles pré-entraînés. Cette approche de transfer learning démontre l’importance de l’adaptation domaine-spécifique dans la génération musicale émotionnelle.
L’analyse comparative des configurations mémoire (ON vs OFF) et d’attention (partielle vs absolue) révèle des compromis intéressants entre qualité générative et efficacité computationnelle. La configuration mémoire activée améliore la cohérence à long terme au coût d’une complexité accrue.
Applications pratiques et perspectives d’avenir
Domaines d’application
Les applications potentielles du système ITEM s’étendent à de nombreux domaines créatifs et thérapeutiques. Dans l’industrie du divertissement, la technologie peut automatiser la création de bandes sonores pour contenus multimédias, réduisant significativement les coûts et délais de production.
Le domaine thérapeutique représente une application particulièrement prometteuse. La génération de musique personnalisée basée sur l’état émotionnel du patient, détecté par analyse d’images ou de vidéos, ouvre des perspectives innovantes en musicothérapie et accompagnement psychologique.
L’éducation artistique constitue un autre domaine d’application majeur. Le système peut servir d’outil pédagogique pour illustrer les correspondances entre expression visuelle et musicale, enrichissant l’apprentissage artistique interdisciplinaire.
Défis techniques et améliorations futures
Plusieurs axes d’amélioration technique peuvent être identifiés pour les développements futurs. Remplacer les tokens quaternaires (Q1-Q4) par des valeurs continues de valence et arousal permettrait une génération plus précise au niveau émotionnel. L’intégration de modèles de langage musical plus sophistiqués pourrait améliorer la cohérence structurelle des compositions longues. L’incorporation de techniques de génération adversariale pourrait enrichir la diversité et la créativité des outputs musicaux. De plus, le fine-tuning par Apprentissage Renforcé pourrait permettre une granularité plus précise sur les émotions générées.
La personnalisation du système selon les préférences individuelles représente un défi technique fascinant. L’adaptation automatique du style musical selon le profil utilisateur nécessiterait le développement d’architectures d’apprentissage adaptatif sophistiquées.
L’extension vers d’autres modalités sensorielles, incluant la génération d’autres instruments ou la synchronisation avec des éléments visuels dynamiques, ouvrirait des perspectives créatives considérables.
Impact sociétal et considérations éthiques
Le développement d’outils de création artistique automatisée soulève des questions importantes concernant l’authenticité de la démarche créative et les conséquences pour les artistes professionnels. Après avoir principalement exploré les aspects technologiques de ces outils, nous souhaitons désormais orienter nos recherches vers l’accompagnement des artistes, afin de replacer l’humain au cœur du processus de création.
Conclusion
Le projet ITEM (provenant d’AMP) démontre la faisabilité technique de la génération automatique de musique émotionnelle à partir d’images, ouvrant des perspectives révolutionnaires pour la création artistique assistée par intelligence artificielle. L’approche modulaire développée, combinant analyse émotionnelle sophistiquée et génération musicale en deux étapes, produit des résultats qualitatifs encourageants.
Les défis techniques surmontés incluent le développement d’une architecture hybride d’analyse émotionnelle, la création de méthodologies robustes de préprocessing musical et l’implémentation d’une stratégie de génération séquentielle cohérente. Ces contributions techniques constituent des avancées significatives dans les domaines de l’intelligence artificielle créative et de l’informatique musicale.
Les résultats expérimentaux, bien que perfectibles, démontrent la viabilité de l’approche et identifient clairement les axes d’amélioration futurs. La diversité des applications potentielles, depuis l’industrie du divertissement jusqu’aux applications thérapeutiques, souligne l’impact sociétal considérable de cette technologie.
L’évolution future du système nécessitera une attention particulière aux considérations éthiques et à l’intégration harmonieuse dans l’écosystème créatif existant. La collaboration entre technologistes et artistes s’avère indispensable pour développer des outils qui augmentent plutôt qu’ils ne remplacent la créativité humaine.
