


L’accessibilité PDF est un enjeu mondial, et notamment pour les malvoyants. En effet, 4.3% de la population active est atteinte de déficience visuelle. Seulement 10% des sites web sont accessibles. On appelle un site ou contenu web “accessible” lorsque les personnes, en particulier les personnes en situation de handicap, peuvent accéder au contenu, le comprendre et interagir avec celui-ci.
Pour accéder au contenu web, les personnes déficientes visuelles utilisent des outils d’assistance comme les lecteurs d’écran et les lecteurs braille. Cependant, pour que ces outils fonctionnent correctement, le contenu web doit vérifier les normes d’accessibilité : la norme WCAG 2.1[i] pour les sites web et la norme PDF/UA[ii] pour les fichiers PDF. Le respect de ces normes implique un travail supplémentaire.
En particulier, dans cet article, deux problèmes sont mis en évidence :
- Le non-changement de langue de lecture du lecteur d’écran lors des changements de langue au sein du document.
- La non-description des images par l’outil d’assistance s’il n’y a pas de description associée à l’image.
Figure 1 : exemple d’une mauvaise lecture par le lecteur d’écran
Régler ces problèmes à la main peut être long et fastidieux. Cet article présente donc comment effectuer ces tâches manuelles avec une IA :
- Pour la détection de langues, une IA qui soit capable de donner la langue de chaque mot ;
- Pour la description d’image, une IA qui soit capable de traiter tous les types d’images (logo, image naturelle, graphique).
Ces problématiques ont été traitées dans le cadre d’une collaboration avec l’entreprise DocAxess, spécialisée dans l’utilisation de l’IA pour rendre les PDF accessibles.
Détection de langues
Problématique de la détection multilingue
Lors de la lecture de documents PDF, nous rencontrons plusieurs langues au sein du texte. Or, lors d’une lecture audio, il est nécessaire d’identifier la langue de chaque mot puisque les accents et les prononciations diffèrent d’une langue à une autre. De plus, certains mots sont réutilisés ou repris dans diverses langues.
Cette problématique est en particulier liée au fait que les échanges internationaux ont favorisé l’émergence des mots multilingues. Cela signifie qu’on utilise les mêmes mots dans plusieurs langues, souvent sans modification orthographique significative. Les mots multilingues facilitent la communication et l’interaction à l’échelle mondiale, rendant certaines notions et objets immédiatement reconnaissables partout dans le monde. Ils sont fréquemment issus de la culture populaire, de la technologie, de la science ou de l’interaction historique et commerciale entre différentes régions et peuples (virus, robot, taxi, karaoké, cinéma, piano, menu, etc.). C’est pourquoi, même avec une connaissance linguistique approfondie, il peut parfois être difficile de déterminer la langue d’un mot.
Vous nous direz que les algorithmes de détection de langues existent déjà depuis longtemps. Nous pensons notamment à Google Traduction qui détecte automatiquement la langue d’un texte. Néanmoins, seule une langue peut être détectée à la fois, peu importe le nombre de langues contenues dans ce texte. C’est dans cette optique que nous cherchons à comprendre le fonctionnement des algorithmes de détection de langues, en particulier leur capacité à identifier avec précision les changements de langue et à les reconnaître.
Identification des langues à l’échelle du mot
Notre domaine de recherche porte sur la détection des alternances codiques, c’est-à-dire le passage d’une langue à une autre au sein d’une même conversation. Nous visons à identifier les langues au niveau du mot afin de repérer les segments monolingues dans un texte multilingue. Cette tâche requiert l’utilisation de techniques de traitement automatique du langage naturel (NLP).

Figure 2 : Représentation des étapes pour la détection des langues
Après avoir sélectionné un texte dont nous souhaitons identifier la langue de chaque mot, il est nécessaire de le nettoyer des éléments indésirables (comme la ponctuation) et de le formater en le tokenisant. Ensuite, nous transmettons ces tokens aux algorithmes de détection de langues. Nous pouvons, par exemple, utiliser des n-grammes ou des modèles de langage (LLM). Enfin, nous obtenons les résultats de la détection au niveau de chaque mot.
Exemple de cas d’usage
Pour illustrer nos propos, nous avons testé un modèle en utilisant une technique de fenêtre glissante sur les textes analysés. Cette fenêtre, composée d’un nombre fixe de mots, se déplace un mot à la fois du début à la fin du texte. À chaque déplacement, l’algorithme de détection de langues calcule un score de probabilité pour chaque langue possible en fonction des mots présents dans la fenêtre. Par exemple, si la fenêtre glissante est de 3 mots et que le texte inclut 5 langues, chaque mot aura 5 probabilités associées à ces langues. Chaque probabilité est une moyenne pondérée des 3 probabilités obtenues à chaque position de la fenêtre glissante.
Figure 3 : Fonctionnement de la fenêtre glissante
Un autre paramètre à considérer est la différence significative entre la probabilité de la langue la plus probable et celle des langues suivantes. Cette différence, définie par un seuil fixe, agit comme un intervalle de confiance lorsque l’algorithme n’est pas certain de la langue du mot. Par exemple, si ce seuil est fixé à 30%, la probabilité de la langue détectée comme la plus probable doit dépasser celles des autres langues de plus de 30%. Si ce n’est pas le cas, une seconde vérification est nécessaire pour confirmer la langue du mot. Cette vérification supplémentaire peut être effectuée par un autre module de détection de langues ou par l’utilisation d’un dictionnaire.
De cette façon, nous retrouvons les langues d’un texte donné à l’échelle du mot. Voici un extrait des résultats obtenus, comprenant les colonnes suivantes : le mot, la langue détectée, le score de probabilité, et le modèle utilisé.
Description d’images
Identifier le besoin des personnes atteintes de déficience visuelle
Pour qu’une personne atteinte de déficience visuelle puisse avoir accès aux informations d’une image, il faut que celle-ci soit associée à une description, or ce n’est généralement pas le cas : c’est un travail à effectuer au moment de la création d’un contenu, ce qui est laborieux , mais qui pourtant est nécessaire. En effet, lorsqu’une image n’est pas décrite ou mal décrite (des informations sont manquantes ou décrites dans le mauvais ordre), il est impossible de comprendre ce qu’elle représente.
Un premier besoin évident pour une bonne description d’image est donc que cette description soit complète et correcte.
Mais il existe d’autres critères, moins flagrants, comme le fait qu’une description ne doit pas inclure d’informations de mise en forme comme des couleurs ou des positions : ce sont des informations non nécessaires pour des personnes malvoyantes ou aveugles, qui vont amener un surplus d’informations et rendre plus difficile la compréhension de l’image pour ces personnes.
Le graphique est divisé comme suit :
- Gestion de l’épargne et Assurances : 38%
- Grandes clientèles : 29%
- Services financiers spécialisés : 17%
- Banque de proximité : 16%
Figure 4 : exemple d’une image et sa description générée par IA
Comprendre l’architecture des modèles d’IA pour la description d’images
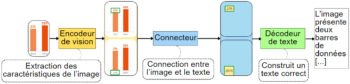
Figure 5 : schéma de l’architecture d’un modèle d’IA pour la description d’images
L’architecture classique utilisée pour les modèles de descriptions d’images est celle de la Figure 2. Il s’agit d’un ensemble de modules et de sous-modèles permettant de gérer à la fois l’image et le texte. Le modèle dans son entièreté comprend :
- Un encodeur de vision : cette partie permet d’extraire les caractéristiques principales de l’image sous forme d’un vecteur. Les modèles de descriptions d’images utilisent initialement des réseaux de neurones convolutifs pour ce module, et plus récemment, des transformer de vision sont utilisés comme le modèle ViT[iii] ;
- Un connecteur : ce module permet de connecter la partie image et la partie texte. Il s’agit soit d’une couche classique de réseau de neurones, soit d’un module plus complexe constitué d’un ensemble de paramètres à apprendre, ou encore d’un modèle expert permettant de passer d’une information visuelle à une information textuelle ;
- Un décodeur de texte : la génération de texte est effectuée par le décodeur de texte. À partir des informations qui lui sont données par le connecteur, ce module construit un texte cohérent et syntaxiquement correct. Les modèles utilisés aujourd’hui sont des LLM comme Llama 2[iv] ou Mistral[v].
Pour pouvoir développer ce genre de modèles, des technologies classiquement utilisées sont Python, avec les bibliothèques transformers et PyTorch.
Les modèles pouvant être assez lourds, une solution peut être d’utiliser des plateformes comme Replicate ou Amazon EC2 pour héberger les modèles.
Choisir son modèle et l’améliorer
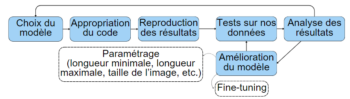
Figure 6 : étapes pour le choix d’un modèle de description d’images
Il existe de nombreux modèles de description d’images différents. Ainsi, pour choisir lequel correspond le mieux à nos besoins, on peut suivre la méthode de la figure :
- Choisir un modèle ;
- Récupérer le code du modèle (par exemple sur GitHub) et le modifier pour réussir à l’utiliser ;
- Reproduire les résultats présentés dans l’article du modèle pour s’assurer qu’il est correctement installé : la plupart des modèles sont publiés avec un article les expliquant et présentant leurs performances sur certains jeux de données particuliers ;
- Tester le modèle sur nos propres données ;
- Analyser les résultats : c’est une étape manuelle, en effet, il n’y a pas de bonnes métriques pour la tâche de description d’images, une façon d’automatiser cette étape est d’utiliser un modèle type GPT[vi] pour donner une note sur cinq à la description ;
- Améliorer le modèle : cela peut passer par un changement dans les paramètres du modèle (longueur de description plus longue ou plus courte, taille de l’image en entrée, etc.) ou dans un entraînement (fine-tuning) du modèle sur un nouveau jeu de données et une tâche spécialisée ;
- Puis de nouveau tester sur nos données, analyser les résultats et améliorer le modèle, jusqu’à ce qu’on ne puisse plus l’améliorer et qu’on teste un nouveau modèle.
Toutes ces étapes permettent de déterminer le modèle adapté à nos besoins et de l’améliorer dans le but d’obtenir les meilleurs résultats possibles.
Conclusion
Nous avons vu comment utiliser l’IA pour faciliter l’accessibilité des fichiers PDF pour la description d’image et la détection de langue.
Si vous souhaitez en apprendre davantage sur l’accessibilité numérique, vous pouvez consulter le blog DocAxess et le blog Ipedis. Ces entreprises sont respectivement spécialisées dans l’accessibilité PDF et l’accessibilité des sites web.
[i] Règles pour l’accessibilité des contenus Web (WCAG) 2.1 (w3.org)
[ii] La norme PDF/UA expliquée de A à Z – DocAxess – Aller à la page d’accueil
[iii] [2010.11929] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale (arxiv.org)
[iv] [2307.09288] Llama 2: Open Foundation and Fine-Tuned Chat Models (arxiv.org)
[v] [2310.06825] Mistral 7B (arxiv.org)
[vi] language_understanding_paper.pdf (openai.com)