


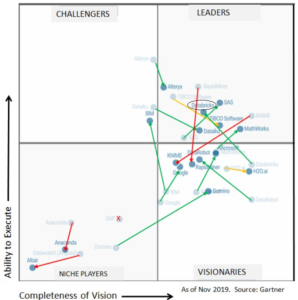
Dans le dernier rapport Magic Quadrant Gartner 2020 consacré aux plateformes Data Science, Databricks a été nommée leader dans la catégorie des plateformes de Data Science et de Machine Learning.
C’est la troisième année consécutive que Gartner reconnaît Databricks dans ce Magic Quadrant.
Cet article s’intéressera particulièrement aux aspects techniques de Databricks au travers de ses fonctionnalités Cloud (interopérabilité avec Azure et AWS) et de son Notebook. Nous explorerons ces différentes fonctionnalités, et nous présenterons quelques témoignages clients sur les avantages de Databricks Unified Analytics Platform , avant de s’intéresser aux dernières nouveautées annoncées lors du Spark+AI Summit 2020.
Databricks
Databricks est une société américaine fondée par les créateurs originaux d’Apache Spark. Databricks est issue du projet AMPLab de l’université de Californie à Berkeley, qui a participé à la création d’Apache Spark. Spark permet notamment d’analyser de très grands ensembles de données sur plusieurs serveurs.
Databricks se distingue par sa plateforme appelée “ The Unified Analytics Platform” qui est une plateforme fiable et évolutive pour vos pipelines de données, vos lacs et vos plateformes de données. Elle gère l’ensemble du workflow des données, avec une intervention humaine moindre pour les tâches d’analyse complexes, afin de pouvoir ingérer, traiter, stocker et exposer les données dans toute votre organisation.
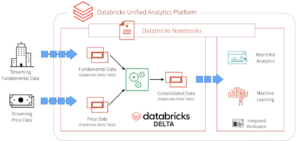
Elle se distingue notamment par sa solution “Enterprise Cloud Service” qui fournit une sécurité native, une administration simple à l’échelle de l’organisation et une automatisation à grande échelle pour la plateforme Unified Data Analytics sur plusieurs clouds (AWS, Azure)
Notebook Databricks vs les Notebooks concurrents
Dans le monde de la Data, les Notebooks sont devenus indispensables. les Notebooks ce sont des formes de site web interactif personnalisable (wiki) dans lequel les utilisateurs écrivent et exécutent du code, visualisent les résultats et partagent leurs travaux. En général, les Data Scientists utilisent les Notebooks pour des POC et des tâches d’exploration de données.
Nous commençons, de plus en plus, à voir d’autres groupes tirer parti de l’outil, notamment des analystes commerciaux et des ingénieurs analytiques. Netflix est un excellent exemple d’entreprise qui exploite les Notebooks dans ses différentes unités fonctionnelles ; à travers son Notebook interne appelé Polynote.
Le nombre des Notebooks a proliféré ces dernières années (voir la figure ci-dessous). Ils sont en open source ou hébergés. Les Notebooks open source incluent Jupyter et Apache Zeppelin. Les offres hébergées incluent Deepnote, Databricks Collaborative Notebooks, Google Colab. Certains Notebooks peuvent même exécuter du code à partir de plusieurs langages comme Polynote.
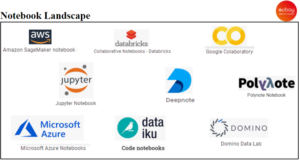
En raison de sa flexibilité et de son interactivité, Jupyter a explosé en popularité parmi les Data Scientists. Selon NBViewer, il existe aujourd’hui plus de 7 millions de Notebooks Jupyter publics sur GitHub (source: NBViewer Survey )
Google colab quant à lui commence à gagner en popularité, en se distinguant par un accès à des processeurs graphiques GPU, ce qui permet de développer des applications en Deep Learning en utilisant des bibliothèques Python populaires telles que Keras, TensorFlow, PyTorch et OpenCV.
Cependant la plupart des Notebooks cachent certains problèmes comme :
- La non modularité : Jupyter encourage à mettre la plupart du code directement dans les cellules afin d’utiliser au mieux les outils interactifs. Il est impossible donc de créer vos propres librairies afin de les partager dans plusieurs Notebooks.
- Difficulté à tester : Pour les mêmes raisons de modularité décrites ci-dessus, il est difficile de tester les Notebooks à l’aide des moyens de test unitaires traditionnels. Les tests demeurent importants pour garantir la qualité du code.
- Contrôle de version : Les Notebooks n’assurent pas un bon contrôle de version. Même s’il existe des outils de contrôle de version comme Git, qui permet de différencier et fusionner les Notebooks Jupyter (notebook diffing and merging ) mais ça reste moins efficace.
- Debugging: Jupyter ne présente pas une façon pour mieux debugger le code, comme il est possible dans des IDE (Pycharm, Spyder…)
(PixieDebugger: the-visual-python-debugger-for-jupyter-notebooks)
Les Notebooks sont parfaits pour l’exploration et le prototypage rapide. Ils ne sont certainement pas conçus pour être réutilisés ou utilisés en production mais cela reste possible en les transformant en code natif.
Databricks Collaborative Notebook vient pour remédier à certains de ces challenges, de plus, il présente différents avantages comme permettre de :
- Effectuer une exploration rapide des données scientifiques,
- Créer des modèles du Machine Learning supportant plusieurs langages à savoir : Python, Java, Scala, R,
- Réaliser de la Data visualisation intégrée,
- Garantir une gestion automatique des versions, et une opérationnalisation avec des tâches.
Cet aspect collaboratif du Notebook Databricks permet à la fois d’accélérer la productivité et l’innovation.
Parmi ces avantages aussi:
- Travailler Ensemble : Partager des Notebooks et travailler avec des pairs dans plusieurs langages (R, Python, SQL et Scala) et bibliothèques de votre choix.
- Opérationnaliser à l’échelle : Planifier des Notebooks pour exécuter automatiquement l’apprentissage automatique et des pipelines de données à grande échelle.
- Accès aux données : Accéder rapidement aux ensembles de données disponibles ou se connecter à n’importe quelle source de données, sur site ou dans le cloud.
- Contrôle de version automatique : Le suivi des modifications et le contrôle des versions effectué automatiquement.
- Visualisations interactives : Visualiser des informations grâce à un large éventail de visualisations pointer-cliquer. Ou utilisez de puissantes options scriptables telles que matplotlib, ggplot et D3.
- Intégrations : Se connecter à Tableau, Looker, PowerBI, RStudio, SnowFlake, etc. permettant aux Data Scientists et aux ingénieurs d’utiliser des outils familiers.
Databricks cloud (azure vs aws)
Certains clients sont familiers avec l’écosystème Hadoop sur on-premise. De ce fait ils savent sans doute que l’un des plus gros problèmes de cette plate-forme est le coût consacré au support et à la maintenance de l’infrastructure qui prend en charge la plate-forme. Ces défis incluent :
- La configuration des serveurs et réseau,
- Le stockage,
- L’installation de logiciels,
- La configuration des meilleures pratiques pour les technologies déployées.
Databricks Unified Data Analytics, vient pour alléger ces complexités impliquées dans l’exécution et la maintenance d’infrastructure et permet aux développeurs de se concentrer sur la création de valeur métier.
Pour bénéficier au mieux de la puissance Cloud, Databricks propose une interopérabilité avec les services des deux principaux cloud public actuels : Amazon Web Services et Microsoft Azure (AWS et AZURE)
Un comparatif des services AWS et Azure est présenté sur l’infographie suivante :

Quelques témoignages client sur les avantages de Databricks Unified Analytics Platform

Dernières nouveautés & Conclusion
Lors de son dernier “AI Spark summit 2020”: évènement incontournable dans le monde du Big Data et de l’IA, Databricks a présenté les nouveautés de sa plateforme sous différents aspects à savoir: Delta Lake et Koalas pour la Data Processing, MLFlow pour le Machine Learning, et Kubernetes pour le DevOps.
Une grande importance a été donné à son produit phare “Delta Lake” qui permet aux ingénieurs de se concentrer sur la préparation et l’extraction de la valeur des données.
Delta Lake utilise Spark comme moteur pour le processing et permet de rassembler le batch et le streaming.
La dernière version Delta Lake 0.7.0, contient désormais plus de fonctionnalités (delta lake 0.7.0 Features) comme le support d’Azure Data Lake Storage Gen2.
Databricks a pour objectif de créer une plateforme unifiée pour tous les ingénieurs Data (Data Analysts, Data Engineers, et Data Scientists) qui grâce à des projets comme Delta Lake et MLflow, peuvent travailler en toute harmonie.
