


Le terme Modern Data Stack (MDS) est depuis quelques années très à la mode. Tellement « hype » que certaines sociétés spécialisées (éditeurs ou sociétés de conseil) ont voulu déposer le terme pour « s’approprier » le concept. Mais, être tendance ne veut pas toujours dire être un effet de mode et impliquer d’être éphémère.
Alors, la Modern Data Stack, quezako ?
Au sens littéral, une MDS est un empilement de technologies Data modernes. Plus précisément, cet empilement se fait en mode « best-of-breed » afin de disposer théoriquement de la « meilleure » technologie pour chacune des briques (chaque brique servant un objectif distinct) composant une plateforme Data. L’objectif est donc de mettre en œuvre une plateforme Data offrant à la fois efficacité, performance et robustesse à ses utilisateurs au sens large, qu’ils soient techniques ou métiers.
Mais alors d’où le paradigme MDS prend son origine ?
Le point d’origine se situe au moment de l’émergence et plus exactement de l’avènement des solutions Cloud Data Warehouse (DW). Véritable rupture technologique avec les principes BI et Big Data, ces solutions ont notamment permis de combler le fossé technologique entre le Data Warehouse et le Data Lake et de les rassembler et rapprocher en termes d’architecture et d’usages.
Grâce à l’architecture novatrice des Cloud DW, le paradigme d’intégration des données a pu évoluer, passant d’une approche classiquement ETL à une approche ELT avec une dissociation « nette » entre l’ingestion des données et la transformation des données. L’ingestion et la transformation pouvant dorénavant être réalisées à des moments différents et par des personas Data différentes.
Les besoins en termes de Self-Service et d’autonomie des métiers ont aussi été déterminant dans l’émergence des MDS. La modernité de l’architecture et notamment la dissociation de l’ingestion et du traitement des données a aussi permis de remonter l’autonomie des métiers plus haut dans la chaîne de gestion des données : les profils techniques se chargeant de l’architecture et de l’ingestion des données et les profils plus proches des métiers de la transformation et de la valorisation des données.
La Modern Data Stack est donc aujourd’hui devenue un terme pour décrire le changement de cap des plateformes Data qui sont passées d’un « design » basé sur une vision IT à un « design » basé sur une vision Métier et cela grâce à l’innovation IT dans le domaine de la Data de ces dernières années.
En résumé, opter pour une Modern Data Stack a pour objectif de rendre la donnée actionnable par le plus grand nombre. De facto, l’approche permet aux organisations de devenir « Data Driven » plus rapidement et plus efficacement. Qui plus est tout en étant aligné avec des modèles opérationnels et organisationnels tels que l’approche Data Mesh.
Qui dit MDS dit architecture moderne et innovante !
D’un point de vue technique, une MDS se différencie d’une Data Stack dite « Legacy » (ou tout simplement classique) de la manière suivante :
- Une MDS est construite autour d’un Cloud DWS et est donc « cloud-first » par définition ;
- L’architecture d’une MDS repose sur un pattern inspiré des architectures micro-services et de ce fait permet une meilleure interopérabilité et donc une plus grande flexibilité technologique. D’où la modularité d’une MDS ;
- Chaque brique est le plus souvent basée sur des services managés (voir « Serverless ») pour rester dans la logique d’efficacité et de simplicité ;
- Le tout reposant sur des langages populaires doublés d’une grande accessibilité tels que SQL ou Python. Sur ce point, la MDS se caractérise plutôt par un « back to basic » que par une approche de modernisation.
Au-delà de ses caractéristiques techniques, une MDS typique repose (du moins en partie) sur les briques suivantes :
- Le stockage des données avec obligatoirement un Cloud DW ;
- L’ingestion (extraction et chargement) des données ;
- La transformation des données ;
- La valorisation des données avec une solution de BI moderne et/ou une plateforme de Data Science & IA ;
- L’activation des données avec un Reverse ETL.
A cela s’ajoute des fonctionnalités de support et d’assistance à l’exploitation et à la gouvernance de la MDS :
- L’orchestration de la pile technologique et des traitements de données ;
- L’observabilité des données ;
- La gouvernance des données.
Pour illustrer la présentation des caractéristiques technique d’une MDS, voici une vue (représentative mais non-exhaustive pour des questions de lisibilité) de son écosystème technologique :
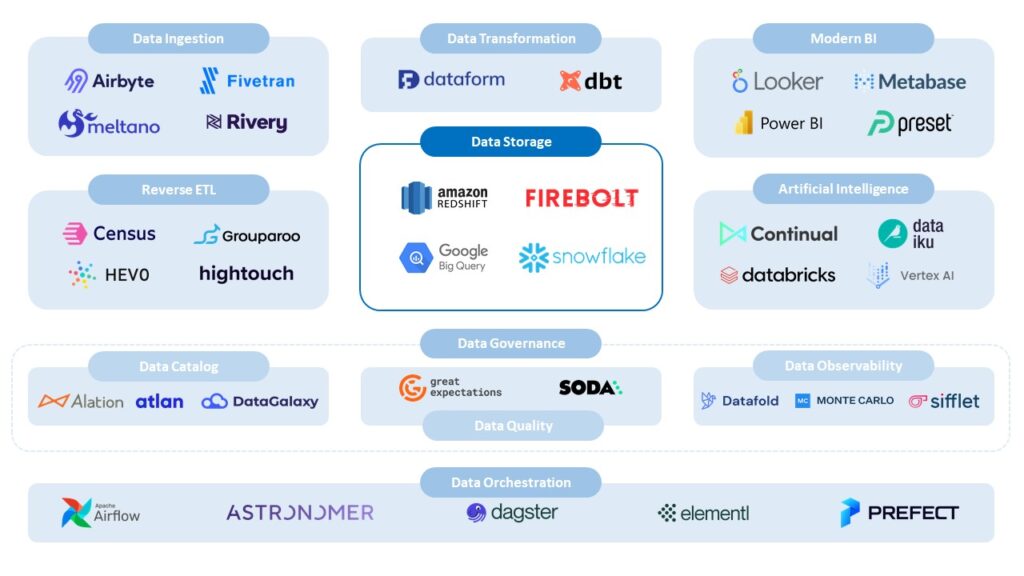
Stockage de données : Le rôle pivot du Cloud DW au sein de la MDS
Comme indiqué précédemment, le stockage des données est centré sur les fonctionnalités (du moins les caractéristiques) d’un Cloud DW adressé par des technologies spécialisées ou des technologies les supportant (le cas par exemple des architectures de type Data Lakehouse).
Les technologies les plus populaires sont principalement proposées par deux catégories d’éditeurs :
- Les trois principaux fournisseurs du cloud public : Amazon Web Services, Google Cloud et Microsoft Azure ;
- Des éditeurs spécialisés tels que Databricks (pionnier de l’architecture Data Lakehouse) et Snowflake (le game changer du Data Warehouse-as-a-Service devenu en quelques années un des leaders de son marché).

Note : Statistiques en date du 19/4/2023 – Les 3 solutions ayant le plus de votes
Source : https://www.gartner.com/peer-insights/
Même significativement trusté par une poignée de solutions, le marché des Cloud DW reste un marché dynamique et attractif avec, ces dernières années, l’arrivée de nouveaux entrants tels que :
- La société Firebolt créée en 2019 par des anciens de Sisense et ayant déjà levé 264 M$ (dont une série C de 100 M$ en janvier 2022) afin de proposer un Cloud DW éponyme hautement performant et à faible latence ;
- Databend (https://databend.rs/), un Cloud DW open source créé en mars 2021 par la société Datafuse Labs, Inc et se voulant être une alternative à Snowflake. Depuis mars 2023, la solution est disponible sous la forme d’un service managé en version Beta.
De l’ETL à l’ELT : Le retour en force du SQL dans l’ingénierie de données
Au sein des architectures orientées Big Data, les pipelines de données sont implémentés de manière à extraire, transformer et charger (ETL) les données via des applications Spark développées avec les langages Scala ou Python. Historiquement, à l’époque de la Business Intelligence, l’intégration des données était réalisée avec des solutions ETL, c’est-à-dire en mode « low-code » et avec du code SQL (ou équivalent). Bien que les langages sous-jacents soient « standards », ces solutions reposent le plus souvent sur des moteurs propriétaires et ne proposent que des connecteurs de données adaptés aux architectures traditionnelles (fichiers, SGBD et ERP).
Traditionnellement et dans une majorité des cas, l’intégration des données repose donc sur une approche ETL implémentée avec une seule solution pour réaliser l’ensemble des actions sur les données (extraction, transformation et chargement). Le tout à la main de personas Data orientées IT.
Dans le contexte de la MDS, le paradigme utilisé évolue vers une approche ELT ou plus précisément EL-T puisque les briques sont dissociées et spécialisées en termes d’outillage :
- Un outil EL pour mettre en œuvre des pipelines de données afin de charger dans le DW des données provenant de sources de données variées et modernes ;
- Un outil T pour réaliser les transformations de données directement dans le DW.
Les solutions EL telles que Fivetran et Airbyte sont donc des facilitateurs et accélérateurs d’’extraction et de chargement des données. Ces solutions sont totalement managées et comprennent des centaines de connecteurs prêts à l’emploi et maintenus en permanence (par exemple, Salesforce, Hubspot, Zendesk,…). La maintenance des connecteurs est un point déterminant dans le recours à ce type de solutions puisqu’une MDS s’inscrit dans un environnement « Cloud-first » (le Cloud étant à la fois l’œuf et la poule dans ce contexte) et est donc composée de solutions évoluant en permanence et de manière indépendante les unes des autres.
Une fois les données chargées et disponibles dans le Cloud DW, l’approche ELT prend tout son sens et la transformation des données peut être alors réalisée par un outil spécialisé et par tout profil maitrisant le langage SQL. C’est dans ce contexte que le SQL revient en force après une traversée du désert liée à l’avènement des technologies Big Data au cours des années 2010.
Aujourd’hui, dbt (data build tool) de l’éditeur dbt Labs est l’outil de référence au sein des MDS pour transformer les données via des scripts SQL depuis un Cloud DW. Au-delà de ces fonctionnalités, dbt permet de modéliser et documenter les données de manière collaborative et reproductible. A la manière d’un framework, dbt pose donc un cadre pratique de transformation de données qui permet aux spécialistes Data, quels qu’ils soient, de délivrer de la donnée de confiance de manière rapide et efficace. La transformation des données se démocratisant, un « nouveau » rôle (fortement marketé par dbt Labs) a pu émerger pour accélérer la motorisation d’une stratégie « Data Driven » : l’Analytics Engineer.
D’un point de vue technologique, sur le segment spécifique des outils T, il n’existe que très peu de concurrents directs à dbt. L’un des rares est Dataform qui a été acquis par Google Cloud en décembre 2020. Néanmoins, de nombreux éditeurs plus généralistes (notamment les éditeurs d’iPaaS) se positionnent sur ce marché. Un fait marquant démontrant l’intérêt de l’industrie pour ce segment est le positionnement de Databricks sur l’approche ELT avec Databricks SQL et son récent partenariat avec dbt Labs.
L’orchestration des données : L’indispensable pour une ingénierie des données industrielle
La Data Orchestration consiste à automatiser et à surveiller l’exécution de l’ensemble des activités liées au cycle de vie des données au sein de la MDS (collecte, stockage, traitement et exposition – ou mise à disposition) afin de permettre aux utilisateurs de les exploiter de manière simple et efficace.
Une MDS étant par définition un assemblage d’un grand nombre d’outils différents, la mise en œuvre de l’orchestration peut s’avérer particulièrement complexe. En effet, un pipeline complet de données peut impliquer de nombreuses connexions à différentes sources de données, de nombreuses étapes avec de multiples processus,…
Dans ce contexte, un outil de Data Orchestration au sein d’une MDS doit donc être capable de proposer une gestion de bout-en-bout des workflows tout en sachant prendre en charge des dépendances hétérogènes et complexes. A défaut d’être « Serverless », un tel outil doit aussi pouvoir s’intégrer de manière transparente aux infrastructures modernes telles que Kubernetes.
Pionniers dans leur domaine, les outils tels que Airflow (par Airbnb) et Luigi (par Spotify) laissent progressivement la place à des plateformes d’orchestration de nouvelle génération comme Prefect et Dagster. Néanmoins, Airflow reste très populaire et très utilisé au sein des MDS et cela au travers de ses différentes déclinaisons sous forme de services managés (citons par exemple, Astro ou Google Cloud Composer).
La MDS : Le levier pour des fonctionnalités exclusives boostant la maturité Data
Le volet « Modern » d’une MDS permet d’exploiter pleinement le potentiel d’une Data Stack.
Un potentiel déjà connu de longue date mais largement simplifié avec la MDS est l’activation des données, c’est-à-dire mettre en place une boucle de retour des données, une fois raffinées et disponibles sous cette forme dans le Cloud DW, vers les applications opérationnelles.
En effet, la valorisation des données au travers de la MDS (via une solution BI moderne) est utile pour la prise de décision. Mais, une fois la boucle bouclée (aussi appelée le problème du « dernier kilomètre »), ces données pourront toucher le plus grand nombre des utilisateurs métiers et cela sans être confronté aux problématiques de « Data Democratization ».
Techniquement, l’activation passe par l’utilisation d’un Reverse ETL (même si la logique voudrait que l’outil soit plutôt un Reverse EL puisque le volet Transformation est fondamentalement absent) tels que Hightouch ou Census.
Une autre innovation, propre cette fois-ci aux apports de la MDS, est l’émergence de la Data Observability, c’est-à-dire la capacité à comprendre et maitriser pleinement l’état de santé des données et de ses systèmes.
Cette émergence a pu avoir lieu grâce à l’architecture orientée micro-services de la MDS et donc à ses capacités en termes d’interopérabilité. Chaque brique de la MDS proposant des API pour accéder aux informations détaillées sur son système et les données, les solutions de Data Observability, telles que Monte Carlo et Sifflet, ont su exploiter ces API pour disposer d’une vision 360° des données au sein de la MDS. Cette vision jusqu’alors inégalée couplée à l’historisation des informations recueillies permettent même à ces solutions de proposer des fonctionnalités d’analyse prédictive sur l’état de santé des données et des systèmes.
La MDS et la Data Observability permettent donc d’améliorer la gouvernance au sens large du terme et de ce fait d’accroitre la maturité des organisations sur les données et son exploitation.
La MDS : une véritable plus-value… A condition de respecter les principes fondateurs
S’écarter des principes fondateurs de la MDS est aussi facile que risqué. Sans être dogmatique, il est important de les respecter a minima afin de faire d’une MDS un véritable atout pour le succès d’une stratégie « Data Driven ».
Voici quelques règles à respecter et pièges à éviter pour ce faire :
- L’utilisation optimale de la MDS est liée à l’organisation de l’entreprise et au fait que les métiers disposent d’une autonomie accrue dans la gestion des données et cela y compris en termes de transformation des données. Une MDS sans l’organisation qui va avec reviendrait à disposer d’une Data Stack composée de briques techniques modernes. Mais pas véritablement à une MDS ;
- Qui dit gouvernance simplifiée ne veut pas dire qu’il faut abaisser les moyens mis à disposition pour la mettre en œuvre et la piloter. La gouvernance reste la gouvernance. Si la maturité de l’entreprise est limitée dans ce domaine, mieux vaut commencer par là avant de s’attaquer à la mise en œuvre d’une MDS ;
- Disposer des moyens de ses ambitions pour mener à bien une transformation IT Data vers la MDS est primordial. Il s’agit d’une transformation complexe à mettre en œuvre lorsque le patrimoine (technique et culturel) est important. Cela explique notamment pourquoi les « petites » structures (notamment les entreprises digital natives) performent souvent mieux que les grandes entreprises dans la mise en œuvre d’une MDS. Les moyens et le temps accordé au changement sont des facteurs déterminants dans le succès d’une telle transformation ;
- L’écosystème technologique des MDS est très vaste et en expansion permanente. Sauf à être une entreprise avec un mindset et des compétences très Tech, il est préférable de ne pas céder aux effets de mode et notamment au battage médiatique des grosses levées de fonds (même si celles-ci sont plus raisonnables depuis quelques mois). Mieux vaut choisir des technologies avec un minimum de recul sur le marché local de son entreprise. Cela permettra de rester dans la logique de simplicité et de facilité prônée par le paradigme de la MDS ;
- Même pour une entreprise Tech, il est important de ne pas perdre de vue que la MDS (comme tout système de données en définitive) doit servir le mieux possible les besoins métiers. Une Data Stack techniquement « sexy » ne servira à rien et aura une espérance de vie limitée si elle ne répond pas avant tout aux besoins métiers ;
- Le Cloud apporte de la souplesse en termes d’usage mais sans maitrise des usages, les coûts peuvent exploser. Les usages techniques (par exemple, le volume de données ingéré et traité) sont le plus souvent connus et donc bien maitrisés en termes de consommation Cloud. En revanche, lorsqu’il s’agit des usages métiers et particulièrement du Self-Service (qui est un des bénéfices que doit apporter une MDS), la prédictibilité de la consommation Cloud s’avère complexe. Au risque de voir son ROI passer dans le rouge, il est primordial de surveiller les usages et la consommation associée générée au travers de la MDS.
En conclusion
La MDS peut véritablement permettre aux équipes Data et Métiers de gagner en efficacité et en maturité mais à la condition de faire les bons choix technologiques (évidemment drivés par la vision Métier) et d’évoluer dans une organisation propice à la création de valeur via les innovations apportées par cette dernière.
Cerise sur le gâteau : La MDS permet d’attirer les bons profils Data mais sans forcément avoir besoin en nombre des profils les plus techniques (par exemple, le cas des Data Engineers spécialisés sur les architectures Big Data). Dans un contexte de marché des talents sous tension, la MDS permet d’être productif de manière optimale avec des profils Data plus focus sur les besoins métiers que sur les sujets techniques.
PS : Cet article a été intégralement PAS écrit par ChatGPT.
