


Avril 2028. Michel a fait la fête hier et a un peu de mal à se rappeler de toute sa soirée. Il se réveille dimanche matin et se sert un café, puis prend son téléphone et entame un monotone défilement de son fil TokTok. Et là, Michel n’en revient pas : face à lui, plusieurs photos et vidéos de lui, alcoolisé et discutant avec un ananas. Ces vidéos, il les a postées, mais aussi ses amis, et les algorithmes de TokTok s’en sont déjà emparés. Quelques posts plus bas, réutilisées ou reproduites par d’autres personnes, ces mêmes photos et vidéos. Michel est devenu viral, à son insu. Il réfléchit alors à une solution, à un moyen d’annuler ces posts, mais il n’y en a pas. Il se souvient alors du projet ‘RBL’, présenté en juillet 2024, qui promettait de résoudre ce problème via des opérations chirurgicales et de la manipulation psychologique directement sur les algorithmes. Enterré peu après par le lobby des réseaux et la Convention pour le Droit des IA pour des questions éthiques, Michel se demande ce qu’il se serait passé si ce projet avait vu le jour…
En 2022, la journaliste Melissa Heikkilä a mené plusieurs expériences sur le modèle de langue d’OpenAI GPT-3 afin de déterminer quelles informations pouvaient en être extraites en questionnant le modèle. Elle a ainsi pu obtenir des informations personnelles de son rédacteur en chef au sein du MIT telles que l’adresse de son lieu de travail, sa ville ou le fait qu’il ait une femme et deux filles. Un constat similaire a été fait sur GPT-2 dévoilant numéros de téléphone, noms de rues et adresses de courriel et plus généralement des centaines d’extraits de données utilisées pour entraîner le modèle.
Ces deux exemples montrent que les modèles d’intelligence artificielle (IA), en particulier les modèles de langue, souffrent du phénomène de régurgitation de leurs données d’apprentissage ce qui peut inclure des données à caractère personnel qui ont pu être récupérées d’Internet durant la constitution du jeu de données initial. Selon Carlini et al., au moins 1% des données utilisées pour l’entraînement d’un modèle peuvent en être extraites et ce chiffre grandit suivant une “échelle log-linéaire” avec la taille du modèle (son nombre de paramètres). Les modèles étant de plus en plus massifs, GPT-4 étant par exemple 10x plus grand que GPT-3, ce risque de voir nos informations personnelles exposées au plus grand nombre est d’autant plus important.
Un autre cas préoccupant de cette ruée à la donnée relève de l’utilisation de données soumises à des droits d’auteur dans les jeux d’entraînement des modèles. C’est, par exemple, ce qu’il s’est produit avec l’entreprise Samsung en 2023 qui avait vu certain-es de ses employé-es passer des morceaux de codes source propriétaires à ChatGPT dans le but de les aider à les déboguer ou les optimiser. Or, selon les conditions générales d’utilisation de ce chatbot, toute entrée donnée à ChatGPT est envoyée aux serveurs d’OpenAI afin d’être utilisée dans l’entraînement de la prochaine génération de modèle. Ainsi, des codes confidentiels de Samsung sont incorporés dans les modèles GPT. Et comme vu plus haut, il y a des chances qu’en interrogeant le modèle ces mêmes codes ressortent tels quels, ce qui pose un réel problème de propriété intellectuelle.
On arrive donc à un questionnement sur l’utilisation de nos données personnelles et propriétés intellectuelles dans l’entraînement des modèles d’intelligence artificielle. En effet, une masse de plus en plus importante de données est nécessaire pour entraîner ces modèles, mais comment vérifier la présence de données sensibles dans des ensembles si importants ? Et que faire si le modèle a déjà été entraîné sur ces données ? Heureusement, pour répondre à ces interrogations, un tout nouveau champ de recherche appelé Désapprentissage Machine (ou Machine Unlearning en anglais) a été ouvert, et dans cet article nous allons aborder ses grands principes ainsi que les différentes approches que nous avons développées au sein de Aubay Innov.
Qu’est-ce que le désapprentissage
Le Machine Unlearning est un processus par lequel un modèle d’apprentissage automatique, ou intelligence artificielle, est modifié pour oublier certaines données spécifiques sans nécessiter une réinitialisation complète et un réentraînement à partir de zéro du fait du coût important de l’entraînement de modèles.
Le désapprentissage est une tâche assez délicate, car on ne maîtrise pas la localisation exacte des informations que possède un modèle d’IA et que l’on souhaite malgré tout conserver ses performances.
Pourquoi désapprendre
Désapprendre un modèle d’IA peut avoir plusieurs utilités :
- Correction des erreurs : les modèles d’IA peuvent parfois apprendre à partir de données incorrectes ou contenant des biais (de genre, culturels…). Le désapprentissage permet de corriger ces erreurs en supprimant les informations incorrectes et en rétablissant l’exactitude du modèle ;
- Protection de la vie privée : les modèles d’IA peuvent contenir des informations sensibles ou personnelles qui doivent être supprimées pour protéger la vie privée des individus. Le désapprentissage permet de garantir que ces données ne sont plus accessibles ou utilisées par le modèle ;
- Conformité réglementaire : les réglementations, telles que le RGPD, exigent parfois que les données personnelles soient supprimées des bases de données et des modèles d’IA. Le désapprentissage est nécessaire pour se conformer à ces exigences et éviter les sanctions ou les violations potentielles ;
- Adaptabilité : les environnements et les situations changent avec le temps et les modèles d’IA doivent être capables de s’adapter à ces changements. Le désapprentissage permet de mettre à jour les modèles pour refléter les nouvelles données ou les nouvelles conditions.
Nos méthodes
SASMU : la méthode chirurgicale
Les modèles d’intelligence artificielle sont dotés de plusieurs millions, voire milliards, de neurones leur permettant de modéliser des relations et caractéristiques complexes dans un grand nombre de cas généralisables. Cependant, les mêmes neurones ne sont pas activés pour les mêmes tâches et une très faible proportion d’entre eux est utile à un exemple donné, comme l’illustre l’image ci-dessous. C’est ce qu’on appelle respectivement la sélectivité et la sparsité.
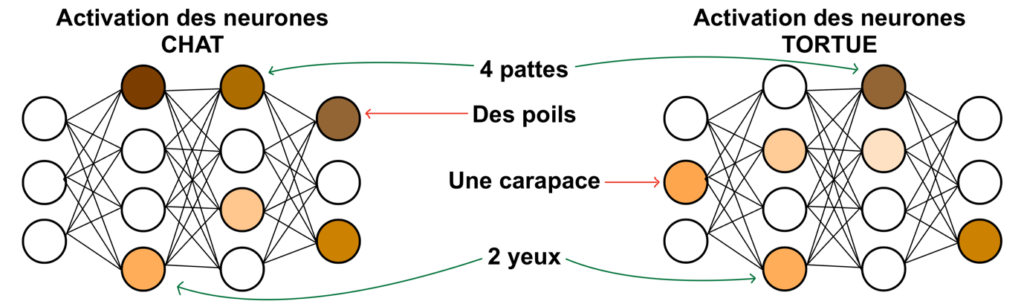
C’est sur cette mécanique que reposent les deux architectures servant de fondation à notre méthode de désapprentissage. En découpant le jeu de données initial en deux sous jeux ‘Forget Set’ (données à oublier) et ‘Remain Set’ (données à garder en mémoire), on va pouvoir déterminer quels sont les neurones les plus importants sur les données que l’on veut oublier, et effectuer le désapprentissage en conséquence.
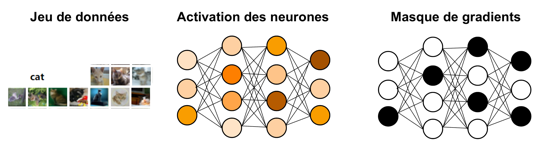
La première architecture se prénomme SalUn , pour Saliency Unlearning. Son principe est simple : On fait passer l’intégralité du ‘Forget Set’ dans le modèle, et on note les gradients obtenus pour chacun des neurones. Un seuillage est ensuite effectué selon la médiane afin de créer un masque binaire n’ayant pour valeur 1 que lorsqu’un neurone est suffisamment actif (et donc important). Un réapprentissage avec des données vérolées est ensuite réalisé en gelant tous les poids du modèle excepté ceux ayant pour valeur 1 dans le masque.
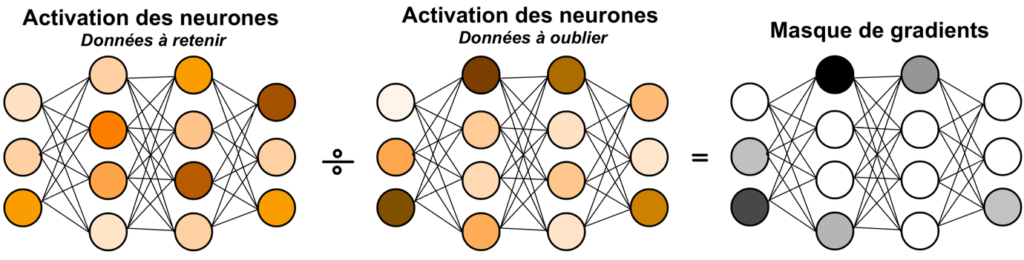
La deuxième architecture, SSD (Selective Synaptic Dampening), va, elle, se baser sur un ratio entre l’activation de chacun des neurones sur le Remain Set et le Forget Set. On va donc faire passer chacun des deux jeux de données dans le modèle séparément et stocker leurs gradients respectifs. Puis générer un masque selon le principe suivant : chaque neurone, s’il possède une activation supérieure sur le Remain Set par rapport au Forget Set, voit son poids atténué d’un certain facteur Beta. Cette méthode, contrairement à SalUn, ne nécessite aucune phase de désapprentissage post-hoc.
En voulant pousser plus loin, on remarque que les 2 architectures ont chacune un défaut :
- SalUn ne prend en compte que l’excitation sur le Forget Set : un neurone peut être important sur le Remain Set également, et sera impacté par le désapprentissage ce qui réduira les performances globales du modèle.
- SSD prend en compte la différence d’activation, mais pas la valeur brute des gradients. Or, un neurone peut-être 10x plus actif sur un jeu que sur l’autre, mais rester relativement inutile dans l’absolu (valeur très faible contre très très faible).
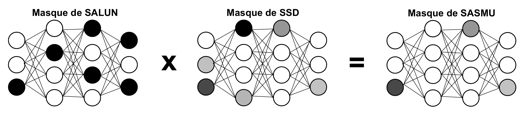
On propose donc une nouvelle architecture : la méthode SASMU (Synaptic Attenuation and Saliency Mapping for Unlearning), fusion de SSD et SalUn, qui va combiner les avantages des deux méthodes susnommées et gommer leurs défauts. En multipliant terme à terme les masques obtenus par chaque méthode, on obtient un nouveau masque dont les valeurs sont comprises entre 0 et 1, qui sera non nul uniquement sur les neurones les plus spécifiques aux données que l’on veut oublier, parmi les neurones les plus actifs.
Ce masque est ensuite utilisé pour réaliser un surapprentissage similaire à celui de SalUn, en inondant le modèle d’informations incorrectes (par exemple associer un label ’chat’ à une image d’oiseau) et en mettant à jour (selon le facteur entre 0 et 1 compris dans le masque) uniquement les neurones qui nous intéressent jusqu’à ce que ceux-ci soient empoisonnés et faussent les prédictions du modèle.

KGAmeha : la manipulation psychologique du modèle
La seconde méthode sur laquelle nous avons travaillé, que nous avons appelé KGAmeha, se base sur des principes très différents de SASMU, se focalisant davantage sur la répartition des données et la consultation de plusieurs modèles. Elle est issue de la fusion de deux architectures de l’Etat de l’Art qui sont SISA et KGA.
SISA, qui signifie Sharded Isolated Sliced and Aggregated, est une méthode de désapprentissage qui consiste à diviser le jeu de données initial en sous-ensembles indépendants et équitablement répartis, appelées shards, et à entraîner un modèle sur chacune de ces shards. Ainsi, on obtient un ensemble de modèles qui vont s’organiser comme un comité d’experts qui, pour prendre une décision (i.e. faire une prédiction), vont avoir recours à un vote à majorité sur leurs prédictions individuelles. Lorsqu’une requête de désapprentissage arrive, la ou les shards contenant les données à oublier sont identifiées et les modèles associés vont être réentraînés de zéro sur leur shard privée des données à oublier.
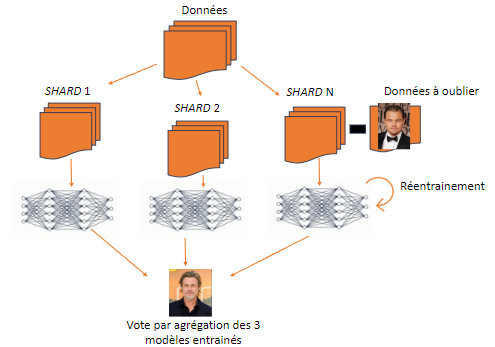
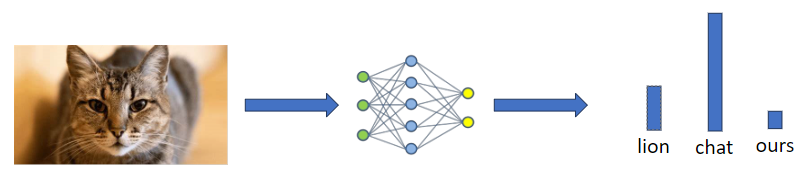
La deuxième architecture nommée KGA (pour Knowledge Gap Alignment) quant à elle se base sur la notion d’écart de connaissances entre modèles. Lorsque l’on donne une donnée à un modèle, il va produire une distribution de probabilités sur les différentes réponses possibles. Par exemple, en donnant une image de chat à un modèle entraîné pour reconnaître divers animaux, il va être sûr à 80% que c’est un chat, à 15% que c’est un lion et 5% que c’est un ours produisant ainsi une distribution comme dans l’illustration ci-dessous.
L’idée derrière ce concept d’écart de connaissances repose sur l’idée que deux modèles entraînés sur des données différentes (D1 et D2) ne vont pas produire la même distribution de probabilités lorsqu’ils sont exposés aux mêmes données (D3) et en calculant la distance entre ces deux distributions, avec la mesure de la divergence KL par exemple, on obtient l’écart de connaissances entre les deux modèles sur les données (D3).
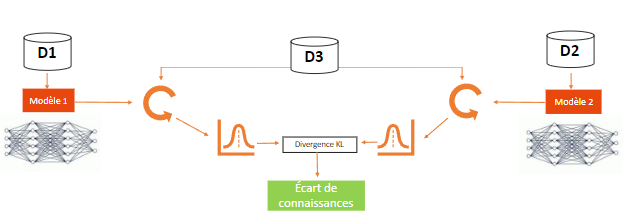
KGA va donc exploiter ce concept en réduisant l’écart de connaissances entre le modèle initial, un modèle entraîné sur les données à oublier et un modèle qui a appris sur des données inconnues du modèle initial. Ainsi, le but de KGA va être d’amener le modèle initial à considérer les données à oublier comme des données qu’il ne connaît pas, un peu comme si on manipulait la “psychologie“ du modèle à qui, à force de répéter qu’il ne connaît pas les données, fini par être convaincu qu’il ne les connaît pas.
Les méthodes SISA et KGA ont toutes deux des avantages et inconvénients :
- SISA permet d’assurer que le modèle a bien oublié les données, comme le modèle contenant les données à oublier a été complètement réentraîné, mais ce réentraînement a un coût en énergie et en temps important ;
- KGA permet un désapprentissage rapide et donne de bons résultats mais nécessite d’entraîner deux modèles : celui sur les données à oublier et sur des données inconnues ce qui implique là aussi un coût énergétique et en temps important.
On propose donc la méthode Fusion KGAmeha, fusion de SISA et KGA, qui permet de pallier les défauts de ces deux architectures. En effet, avec cette approche, les données vont être réparties de la même manière que SISA mais au lieu de réentraîner le ou les modèles contenant des données à oublier c’est KGA qui va être appliquée en entraînant un modèle sur les données à oublier et en utilisant un modèle issu d’une autre shard comme modèle entraîné sur des données inconnues.
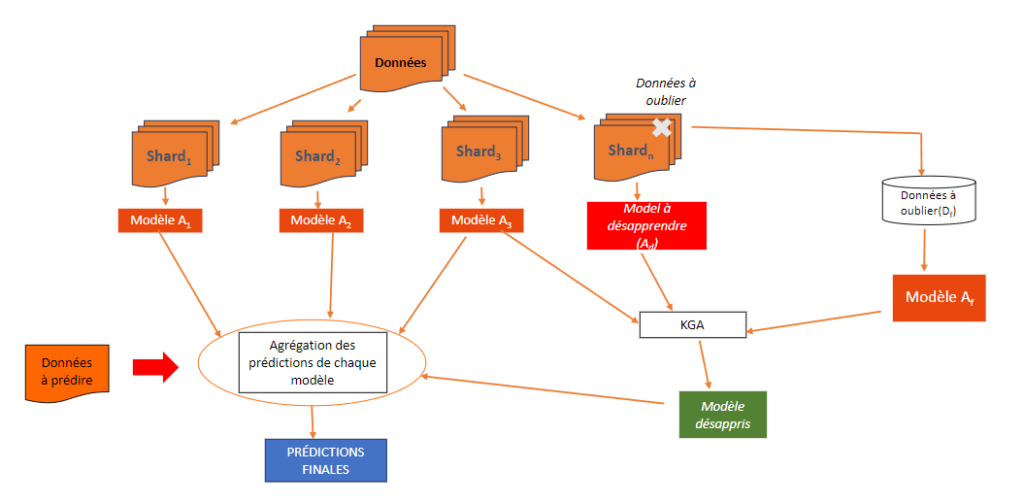
Conclusion avec quelques résultats
Le désapprentissage d’une IA est complexe car nous devons respecter certains critères essentiels :
- Précision : Pourcentage de bonne réponse du modèle sur des nouvelles données. Le modèle doit conserver une haute précision même après le désapprentissage ;
- Taux d’oubli : capacité à vérifier si les données ont été correctement désapprises. Il doit y avoir des mécanismes pour assurer que les données spécifiques ont été supprimées de la mémoire du modèle ;
- Temps : rapidité du processus de désapprentissage. Le processus doit être aussi rapide que possible pour ne pas éterniser les procédures de maintenance et pour une question de coûts.
Le tableau ci-dessous représente les résultats de nos méthodes après le désapprentissage de 100 données (sur 45000 données au total). Le modèle original avait 88% de précision. Pour la méthode de KGAmeha, les 100 données ont été prise dans la même shard.
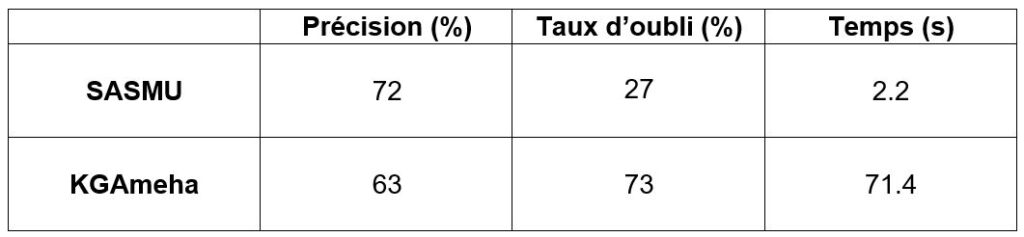
La méthode KGAmeha se distingue par son efficacité pour le désapprentissage des données ciblées. Toutefois, cette efficacité s’accompagne d’une dégradation des performances et d’une augmentation du temps nécessaire à l’exécution. Par conséquent, nous recommandons de privilégier la méthode KGAmeha uniquement lorsque les données à oublier sont localisées dans la même shard. Dans les autres cas, la méthode SASMU demeure une alternative solide.
En conclusion, le domaine du Machine Unlearning en est encore à ses débuts. Compte tenu de son utilité croissante, ce domaine gagne en importance, avec de nouvelles méthodes de désapprentissage qui émergent régulièrement. De plus, à Aubay, notre projet dans ce domaine de recherche se poursuivra l’année prochaine. Nous vous donnons donc rendez-vous dans six mois pour découvrir les nouvelles avancées de nos recherches.
