

")
En effet, là où il est facile d’entrainer un modèle à détecter si une image est un chat ou non et de vérifier le résultat, il est un peu plus compliqué de réaliser cela dans un domaine comme la génération de musique. Il n’y a pas de réponse juste. Une bonne musique peut être mauvaise pour quelqu’un d’autre.
Cependant il existe quand même des méthodes comme celle qui va vous être présentée dans cet article.
Les efforts du projet Aubay Musical Playlist ont été axés sur la création de la partie vocale d’une chanson, incluant à la fois la mélodie chantée et les paroles, à partir d’une composition instrumentale, suivie de la synthèse audio du résultat final. Cette réalisation a été rendue possible grâce au développement d’une application par Aubay Innov’, dans le cadre du projet AMP.
Séparation des composantes musicales pour l’analyse
Une musique est constituée d’instruments et de voix. Il a donc été nécessaire de dissocier ces deux éléments dans les données afin de les fournir séparément aux modèles. Dans un fichier MIDI, chaque instrument est représenté par une piste distincte, mais la piste contenant la mélodie vocale n’est pas toujours nommée “voix” ou “chant”. Pour identifier la bonne piste parmi les différentes présentes dans le fichier, il a fallu comparer le timing des notes avec celui des paroles et sélectionner la piste qui correspond le mieux.
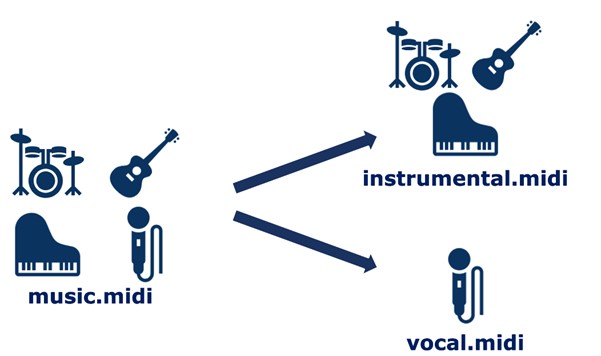
Fonctionnement global :
L’objectif du projet est de créer une mélodie vocale à partir d’une composition instrumentale, ainsi que des paroles basées sur un thème et un style donné, puis de synthétiser la mélodie avec ces paroles. La synthèse de la voix consiste à produire le son et la prononciation des paroles comme si une personne chantait réellement la musique. Cependant, dans ce cas, seuls l’ordinateur, les notes de musique et les syllabes seront utilisés.
Fonctionnement mélodie vocale :
Afin de créer le modèle de mélodie vocale, un modèle de transformer a été utilisé, en l’adaptant pour générer des fichiers musicaux au format .midi. Le modèle a été formé en alimentant l’encodeur avec la partie instrumentale d’une musique et le décodeur avec la partie vocale. Ainsi, le modèle apprend à reproduire la mélodie vocale originale en se basant sur la partie instrumentale, en comparant ce qu’il génère avec la mélodie vocale initiale.
Pour rendre la musique compréhensible pour le modèle, les fichiers midi doivent être “tokenizées”, c’est-à-dire qu’il faut transformer la musique en une suite d’entiers appelés tokens. Chaque token représente un aspect de la musique, par exemple une note, une durée, une position, etc. Miditok a été utilisé, un outil de tokenization de la musique développée par Nathan Fradet lors de sa thèse chez Aubay.

Un exemple de musique tokénizée. ”Bar” représentant une mesure ; ”Pos 0, Tempo 116, Pitch D3, Vel 80, Dur 1.0” représente une note.
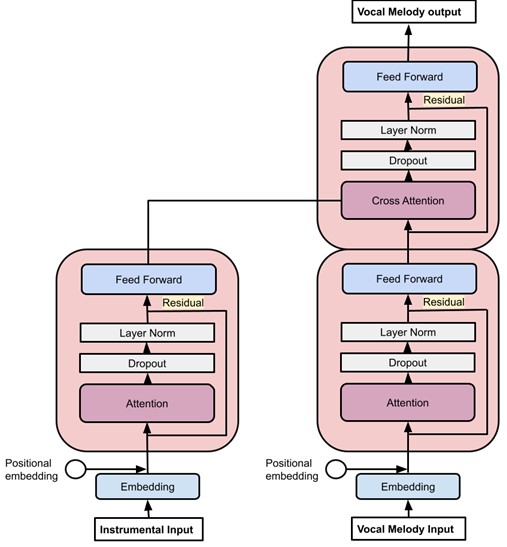
Architecture du transformer de mélodie vocale, à gauche l’encodeur d’instrumental et à droite le décodeur de mélodie vocale.
Pour générer une mélodie vocale, la partie instrumentale est donnée à l’encodeur et un début de séquence vocale est donnée au décodeur. Les tokens sont générés un par un, l’aléatoire de la génération de tokens est contrôlé par différents modes (argmax, categorical ou top-k) qui sont différentes manières de choisir le token suivant. Le modèle peut alors générer des tokens et créer une nouvelle mélodie vocale qui s’adapte bien à la partie instrumentale fournie. Cela permet de composer des musiques innovantes tout en respectant l’harmonie de la partie instrumentale d’origine.
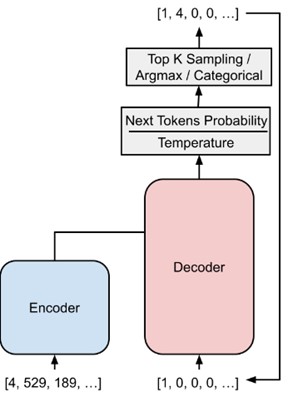
Schéma représentant la génération d’une mélodie vocale
Fonctionnement modèle de paroles :
Pour créer des paroles, des modèles de langage (LLM) sont utilisés. Le modèle est entrainé sur un vaste ensemble de paroles pour qu’il apprenne à structurer des chansons. En plus des paroles, des thèmes lui sont fournis afin de pouvoir générer des paroles en fonction d’un thème précis.
Dans notre cas, nous avons opté pour GPT-Neo d’OpenAI, un modèle plus puissant et rapide que GPT-2, grâce à une meilleure optimisation.
Dû à l’indisponibilité de ressources associant des paroles de chansons à des thèmes, un tout nouveau dataset a été produit. Un dataset a été récupéré sur Kaggle, contenant des millions de paroles de chansons. Afin de leur associer des thèmes, une bibliothèque de topic modeling, BERTopic a été utilisée. Cette bibliothèque regroupe les thèmes récurant en clusters, et en identifiants les mots associés à ces thèmes.
Avec ces nouvelles données bien organisées, le modèle GPT-Neo a été entrainé à associer des paroles à chaque thème et à générer des paroles en fonction du thème donné en entrée.
Deux modèles ont été produits. Un spécifiquement sur des paroles du style rap, et un spécifiquement sur les paroles du style pop. Ainsi, de meilleurs résultats ont pu être obtenus, car les modèles ont été entrainés sur des tâches plus spécifiques.
Fusion de la génération de mélodie et de la génération de paroles :
Afin d’associer les paroles à la mélodie, un système de syllabification a été produit. En effet, les outils disponibles dans la communauté scientifique ne correspondent pas à comment les mots sont décomposés dans la réalité. Ce système repose sur le tokenizer de NLTK qui décompose en syllabes, mais des règles spécifiques à la langue anglaise ont été rajoutés pour une meilleure décomposition.
Par exemple, les mots comme “chance”, où le dernier token est composé de deux lettres et se termine par un “e” (par exemple, “chan”, “ce”). Dans ce cas, le dernier token est prononcé comme faisant partie de la syllabe précédente, donc “chance” est traité comme une seule syllabe. De même, le mot “believe” devrait être prononcé comme “be”, “lieve”, mais le tokenizer pourrait le décomposer en “be”, “lie”, “ve”. Cette règle s’applique à tous les tokens de deux lettres se terminant par un “e”.
Ce genre de règle ont été identifiées au cas par cas pour obtenir un système fonctionnel et réaliste.
Ainsi, la tokenisation de NLTK donne les résultats suivants :
[‘We’, ” ‘”, ‘re ‘, ‘no s’, ‘tran’, ‘ger’, ‘s ‘, ‘to ‘, ‘lo’, ‘ve\nY’, ‘o’, ‘u’, ‘ ‘, ‘kno’, ‘w t’, ‘he ‘, ‘ru’, ‘le’, ‘s an’, ‘d ‘, ‘so ‘, ‘do I’, ‘\nA’, ‘ ‘, ‘ful’, ‘l ‘, ‘com’, ‘mi’, ‘tment’, ” ‘”, ‘s w’, ‘ha’, ‘t I’, ” ‘”, ‘m t’, ‘hin’, ‘kin’, ‘g o’, ‘f\nY’, ‘o’, ‘u’, ‘ ‘, ‘wouldn’, ” ‘”, ‘t ‘, ‘ge’, ‘t t’, ‘hi’, ‘s ‘, ‘fro’, ‘m a’, ‘ny ‘, ‘ot’, ‘he’, ‘r ‘, ‘guy’]
Alors que le système développé par le groupe donne ces résultats :
[“We’re”, ‘no’, ‘stran’, ‘gers’, ‘to’, ‘love’, ‘You’, ‘know’, ‘the’, ‘rules’, ‘and’, ‘so’, ‘do’, ‘I’, ‘A’, ‘full’, ‘com’, ‘mi’, ‘tments’, ‘what’, “I’m”, ‘thin’, ‘king’, ‘of’, ‘You’, ‘would’, ‘nt’, ‘get’, ‘this’, ‘from’, ‘any’, ‘ot’, ‘her’, ‘guy’]
Fonctionnement synthèse de voix :
Afin de générer une voix, il est possible d’utiliser plusieurs techniques d’apprentissage automatique. En analysant les tendances actuelles de l’état de l’art, la technique la plus utilisée aujourd’hui est d’utiliser des modèles de diffusion en passant par les spectrogrammes de MEL de fichier audio, puis de regénérer un fichier audio en utilisant un vocodeur.
Plus concrètement, voici un schéma de modèle possible pour générer une voix chantante.
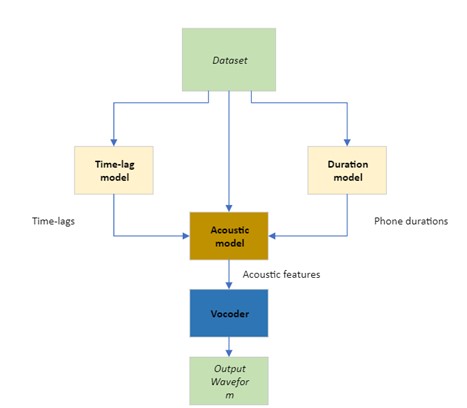
Comme le montre le diagramme ci-dessus, le processus commence par le jeu de données, contenant l’audio du chant et les informations le concernant contenant les paroles et les phonèmes synchronisés sur la musique. Ensuite, le modèle de décalage (time-lag) estime le décalage entre la voix chantée et les informations complémentaires, tandis que le modèle de durée estime la durée pendant laquelle un phonème donné est chanté.
Avec toutes ces informations, le modèle acoustique génère des caractéristiques acoustiques (par exemple un spectrogramme) et les transmet au vocodeur qui génère une voix chantée sous forme d’un fichier audio.

Spectrogramme de MEL : C’est une représentation visuelle des caractéristiques fréquentielles d’un signal audio, particulièrement adaptée à la perception humaine. Elle est basée sur l’échelle de Mel, une échelle de fréquence qui correspond approximativement à la façon dont les humains perçoivent les différences de fréquence sonore.
Un modèle de diffusion en apprentissage automatique est une classe de modèles génératifs qui est utilisée pour générer des données en apprenant à inverser un processus de diffusion stochastique. Ce concept est inspiré par des processus physiques de diffusion, tels que la diffusion de particules dans un milieu, et a récemment gagné en popularité dans le domaine de l’apprentissage automatique, notamment pour la génération d’images.

Un modèle de diffusion en apprentissage automatique est une classe de modèles génératifs qui est utilisée pour générer des données en apprenant à inverser un processus de diffusion stochastique. Ce concept est inspiré par des processus physiques de diffusion, tels que la diffusion de particules dans un milieu, et a récemment gagné en popularité dans le domaine de l’apprentissage automatique, notamment pour la génération d’images.
- Phase de diffusion (dégradation) :
Cette phase implique la corruption progressive des données d’entraînement en ajoutant du bruit au fil du temps. Cela est souvent fait à l’aide d’un processus de Markov, où à chaque étape, une petite quantité de bruit est ajoutée aux données. L’objectif est de rendre les données de plus en plus bruitées jusqu’à ce qu’elles deviennent presque du bruit pur.
- Phase de génération (reconstruction) :
Durant cette phase, le modèle apprend à inverser le processus de diffusion. Autrement dit, il apprend à débruiter progressivement les données bruitées pour revenir aux données originales. Cela est réalisé en utilisant un réseau neuronal entraîné pour estimer la distribution conditionnelle des données à chaque étape de débruitage.
Vocodeur : Outil qui permet d’analyser les principales composantes spectrales de la voix (ou d’un autre son) et fabrique un son synthétique à partir du résultat de cette analyse.
- Entraînement
L’entraînement d’un modèle de diffusion implique généralement l’optimisation des paramètres du modèle (par exemple, les poids d’un réseau de neurones) pour qu’il puisse prédire efficacement les données débruitées à chaque étape. Une méthode courante est de minimiser une forme de perte qui mesure l’erreur entre les étapes générées par le modèle et les étapes originales du processus de diffusion avant.
- Génération
Une fois le modèle entraîné, la génération de nouvelles données se fait en prenant du bruit pur (par exemple, un échantillon de bruit gaussien) et en appliquant le processus de diffusion inverse pas à pas. Cela implique de passer par chaque étape du processus de diffusion inverse, en réduisant progressivement le bruit pour obtenir des données générées.
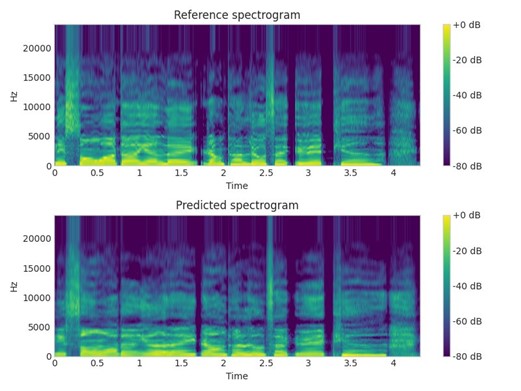
Afin d’illustrer, voici un exemple de spectrogramme qui a pu être généré au sein des travaux sur le sujet. Il est possible de comparer sur cette image deux spectrogrammes entre celui de référence, tiré du jeu de données d’entraînements, et un spectrogramme généré grâce aux méthodes présentées. Bien que l’approche actuelle donne des résultats qui semblent fidèles, il y a encore place à de la recherche pour apporter des améliorations et viser à supprimer les artéfacts qui subsistent dans la génération des modèles d’apprentissage automatique.
Format des données :
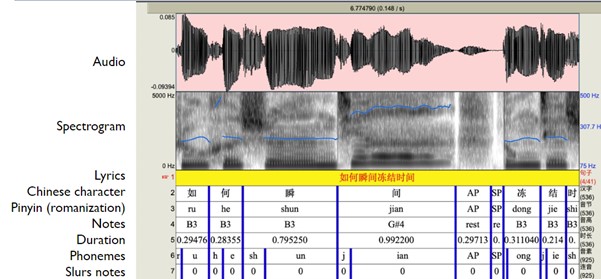
Sur la figure ci-dessus, il est possible de voir une visualisation d’un morceau de chanson tiré du dataset Opencpop. Pour chaque chanson, des informations ont été annotées à la main par l’équipe chargée de créer le dataset. Bien que ce soit un processus long et fastidieux, cela nous a permis de pouvoir mener des travaux sur le sujet.
Pour chaque fichier audio, il est possible de décomposer les annotations en fonction de ce qu’elles représentent.
Tout d’abord, est généré le spectrogramme associé, pour cela il y a trois étapes clés :
- Le signal audio est divisé en segments (ou fenêtres) temporels. Pour chaque segment, une transformation de Fourier rapide (FFT) est appliquée pour convertir le signal du domaine temporel au domaine fréquentiel.
- Les fréquences obtenues par la FFT sont ensuite mappées sur l’échelle de Mel, qui est une échelle perceptuelle basée sur la perception humaine des hauteurs sonores. Cette transformation utilise une banque de filtres de Mel.
- Le spectrogramme de Mel est obtenu en calculant les puissances des fréquences après leur conversion sur l’échelle de Mel. Souvent, une transformation logarithmique est appliquée aux puissances pour imiter la perception humaine de l’intensité sonore.
Ensuite, pour chaque audio, est associé les paroles chantées avec leur décomposition caractère par caractère, et où pour chaque caractère est associé, sa version romanisée (une version phonétique avec des caractères latins), la note sur laquelle la syllabe (le caractère ici) est chantée, le moment et le temps pendant laquelle la syllabe est chantée, puis finalement sa décomposition en phonèmes avec une dernière annotation pour savoir si les notes sont jouées en rapide succession.
Fusion des modèles :

Le pipeline complet consiste à générer une mélodie vocale, puis des paroles, et enfin synthétiser la mélodie avec les paroles de manière à pouvoir écouter le résultat. Cependant, le modèle de synthétisation de voix a été entrainé sur des données en chinois et japonais. Une solution pour lier tout le projet a été de ne faire prononcer qu’une seule syllabe au modèle de synthèse vocale pour mimer un fredonnement. Ainsi, le résultat rend plus humain que simplement une mélodie jouée par une flûte ou un piano.
Conclusion :
Ainsi, grâce à ces étapes présentées plus haut, il est possible de générer la partie vocale d’une musique à partir d’une instrumentale, de la mélodie jusqu’au son complet avec une voix.
En recherche d’une opportunité de carrière dans les métiers de l’IA?
RDV dans notre espace carrière dédié 👉Espace Carrière