

")
Aujourd’hui, je vais vous montrer comment une intelligence artificielle multimodale permet à une personne malvoyante de mieux s’orienter dans un environnement du quotidien, en combinant perception visuelle et raisonnement.
Qu’est-ce qu’une intelligence artificielle multimodale ?
Une intelligence artificielle (IA) multimodale est un type d’intelligence artificielle capable de traiter plusieurs types d’informations en même temps, comme du texte, des images, des sons, ou encore des vidéos. Contrairement à une IA classique qui se concentre souvent sur un seul type de données (par exemple, seulement du texte), une IA multimodale peut comprendre et combiner différentes formes de données pour mieux répondre à une tâche.
Par exemple, une IA multimodale peut analyser une photo tout en lisant une description écrite de cette image, ce qui lui permet de mieux comprendre la situation. Cela ressemble à la manière dont les humains utilisent leurs yeux, leurs oreilles et leur langage pour comprendre le monde autour d’eux.
Ce type d’IA est utilisé dans des domaines variés comme :
- les assistants vocaux intelligents,
- les voitures autonomes,
- ou encore la médecine (où elle peut analyser des radios et lire les rapports médicaux en même temps)
Un autre exemple récent et marquant est GPT-4o d’OpenAI, une IA réellement multimodale capable de comprendre texte, images, audio et de générer des réponses sous forme de texte ou de voix. Elle illustre parfaitement la direction que prend la recherche en IA : des modèles capables de fusionner les sens artificiels pour mieux interagir avec le monde.
Les personnes malvoyantes rencontrent de grandes difficultés à se repérer dans leur environnement habituel surtout en intérieur où les obstacles sont nombreux, variables et peu prévisibles. Le projet Find Your Way (FYW) a pour ambition de leur offrir un véritable assistant visuel intelligent qui leur décrit leur environnement et répond à leurs questions contextuelles.
Dans cette étude de cas, nous allons explorer comment FYW a su allier plusieurs techniques de pointe en IA – SLAM, détection d’objets YOLO (You Only Look Once), et VQA (Visual Question Answering) – pour fournir une solution concrète, portable et adaptable. Une réponse innovante à un problème universel : comment se repérer quand on ne voit pas ?
Naviguer dans votre maison avec aisance grâce à une application révolutionnaire
Se déplacer dans un environnement intérieur, même familier comme sa propre maison, peut représenter un véritable défi pour une personne malvoyante. Un meuble déplacé, une porte entrouverte ou un objet au sol peuvent devenir autant d’obstacles imprévus. C’est pourquoi nous avons conçu une application innovante, pensée pour rendre la navigation en intérieur plus simple, plus sûre et plus intuitive. Il suffit de filmer son environnement et de poser une question à voix haute, pour que l’assistant vous décrive la scène et vous guide vers un objet ou une zone précise. Voyons maintenant comment fonctionne cette technologie, et de quoi elle se compose.
Pour qu’une intelligence artificielle puisse répondre à une question sur une image, elle doit d’abord comprendre ce qu’elle voit. C’est ici qu’intervient YOLOv11 (You Only Look Once), l’un des modèles les plus performants et les plus rapides en matière de détection d’objets en temps réel.
Dans notre projet, YOLOv11 joue un rôle fondamental : c’est le premier module activé une fois qu’une image est capturée par l’utilisateur. Son objectif est d’identifier les objets présents dans la scène, leur emplacement exact et leur type. En d’autres termes, YOLO transforme une image brute en une liste d’objets compréhensibles par la machine.
Comme illustré ci-dessous, YOLOv11 découpe l’image en une grille, puis analyse chaque cellule pour identifier les objets présents, leur catégorie et leur emplacement précis :
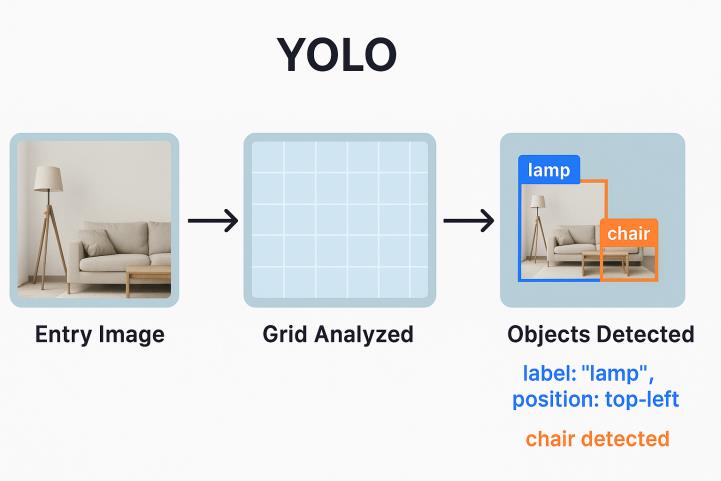
Un modèle à passage unique
Contrairement aux anciens algorithmes de détection qui décomposaient l’image en régions candidates (comme R-CNN), YOLOv11 adopte une approche en une seule passe. Cela signifie que l’image est divisée en une grille, et qu’à chaque cellule de cette grille, le modèle prédit les coordonnées de la bounding box, le label de l’objet détecté (parmi une liste pré-définie) et un score de confiance.
Cette approche permet à YOLOv11 de réaliser une détection extrêmement rapide sans sacrifier la précision. Ce compromis est crucial pour notre cas d’usage, car l’assistant doit fonctionner en temps réel, sur des appareils mobiles à ressources limitées.
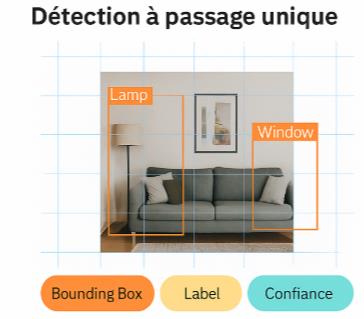
Une détection contextuelle et filtrée
Nous avons personnalisé notre usage de YOLOv11 pour qu’il se concentre uniquement sur des objets pertinents pour les personnes malvoyantes. Plutôt que de détecter des classes génériques, nous avons filtré les objets les plus fréquents et utiles en environnement intérieur : canapé, lampe, lit, fenêtre, porte, chaise, étagère, etc.
De plus, nous avons ajusté le seuil de confiance pour éliminer les détections faibles ou erronées. Le but n’est pas de détecter tout ce qui se trouve dans la scène, mais uniquement ce qui est utile pour formuler une réponse claire à la question de l’utilisateur.

Pourquoi YOLOv11 est central dans notre pipeline ?
Grâce à sa rapidité, sa précision, et sa capacité à s’adapter à des scènes variées, YOLOv11 est le nœud d’entrée essentiel de notre système VQA (Visual Question Answering). Il assure une compréhension visuelle fiable, qui servira de base pour générer une réponse naturelle et contextuelle. Sans une détection robuste, aucune réponse pertinente ne serait possible.
Dans la suite du pipeline, ces données de détection sont traduites en texte, enrichies par la question de l’utilisateur, puis envoyées à MiniCPM pour produire une réponse intelligente.
Faciliter la compréhension de l’environnement grâce à l’IA et aux questions posées par l’utilisateur
Détecter et localiser des objets, c’est bien. Pouvoir poser des questions à l’IA et recevoir une réponse claire, c’est encore mieux. C’est là qu’intervient le module VQA . Le VQA permet à l’utilisateur de poser une question vocale ou textuelle en lien avec la scène analysée, comme :
- Guide-moi jusqu’à la fenêtre ?
- Ou se trouve la télécommande ?
Ce type d’interaction transforme radicalement l’expérience de navigation pour une personne malvoyante. L’utilisateur n’est plus passif : il peut activement interroger son environnement. Cela crée un dialogue avec l’IA qui devient alors un véritable assistant intelligent capable d’interpréter une scène visuelle, de comprendre une question en langage naturel, et d’y répondre avec précision.
Pour permettre au module VQA de comprendre la scène, le système Find Your Way s’appuie sur un processus en plusieurs étapes, depuis la vidéo capturée jusqu’à la génération de la réponse.
Tout commence par la vidéo de l’environnement que l’utilisateur enregistre à l’aide de sa caméra. Cette vidéo est ensuite découpée en images fixes (frames) à intervalles réguliers. Chaque frame est traité indépendamment afin d’en extraire un maximum d’informations utiles.
Les frames de la vidéo sont encodés par le LLM visuel MiniCPM-V int4 qui est une version quantifiée. Ce modèle est capable de traiter des images directement et de produire des représentations vectorielles riches intégrant les détails visuels, les relations spatiales, les couleurs et même des éléments plus subtils.
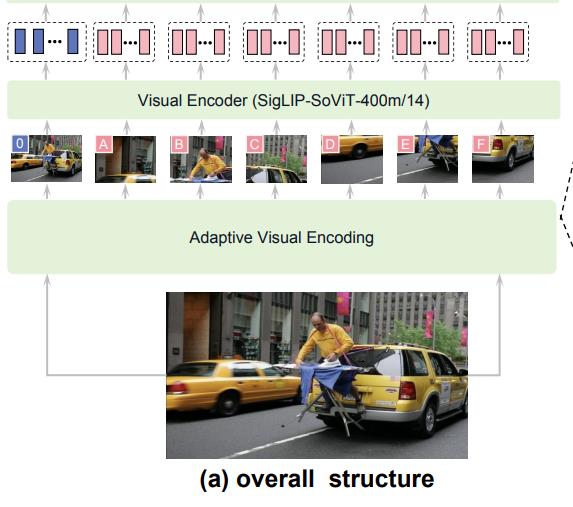
Chaque frame devient alors un vecteur sémantique que l’IA peut utiliser pour raisonner visuellement.
L’étape suivante consiste à fusionner la question de l’utilisateur, les représentations visuelles (issues de MiniCPM), et le contexte textuel (issu de YOLO) dans un prompt enrichi envoyé au modèle. L’ajout des objets détectés ainsi que leurs coordonnées facilitent la compréhension de l’environnement par le LLM.
Voici un exemple concret de l’utilisation qui est possible de faire de l’application :


Une précision accrue grace au SLAM
Le processus de SLAM (Simultaneous Localization and Mapping) permet la création d’une carte 3D à partir d’une entrée vidéo. Cette carte apporte plusieurs avantages. Tout d’abord, elle permet d’apporter une vision beaucoup plus globale de l’environnement, et ce non seulement pour les personnes malvoyantes, mais aussi pour celles susceptibles de les aider. Elle fournit également des données de distance beaucoup plus précises sur l’environnement, même si elles ne sont pas parfaites. Le principal atout du SLAM est sa capacité de localisation en temps réel qui permet de se situer dans n’importe quel environnement, même sans GPS.
SLAM commence par l’analyse d’une vidéo filmée dans un environnement réel. Cette vidéo est d’abord convertie en frames qui servent d’entrée au système. À partir de ces frames, l’algorithme identifie des éléments visuels stables — comme des bords, des textures ou des coins — afin de suivre leur évolution dans le temps et ainsi estimer les déplacements de la caméra.
Grâce à ces estimations, le système est capable de reconstruire en parallèle une carte 3D de l’environnement. Dans notre cas, nous utilisons HI-SLAM2, un algorithme moderne qui combine des techniques de vision par ordinateur avec une méthode de rendu appelée Gaussian Splatting. Celle-ci permet de représenter la scène par un ensemble de petits volumes, ce qui permet une reconstruction efficace et visuellement fidèle.
Afin d’ajouter une dimension sémantique (Identification des objets) à cette carte, nous intégrons également un module de détection d’objets basé sur YOLOv11. Ce dernier permet d’identifier des objets dans les images (comme des chaises, des tables ou des portes) et de les positionner précisément dans la scène 3D. L’association des objets détectés avec les points 3D est effectuée en projetant les coordonnées 3D sur leur frame source et en vérifiant si elles tombent dans les bounding box détectées par YOLO.
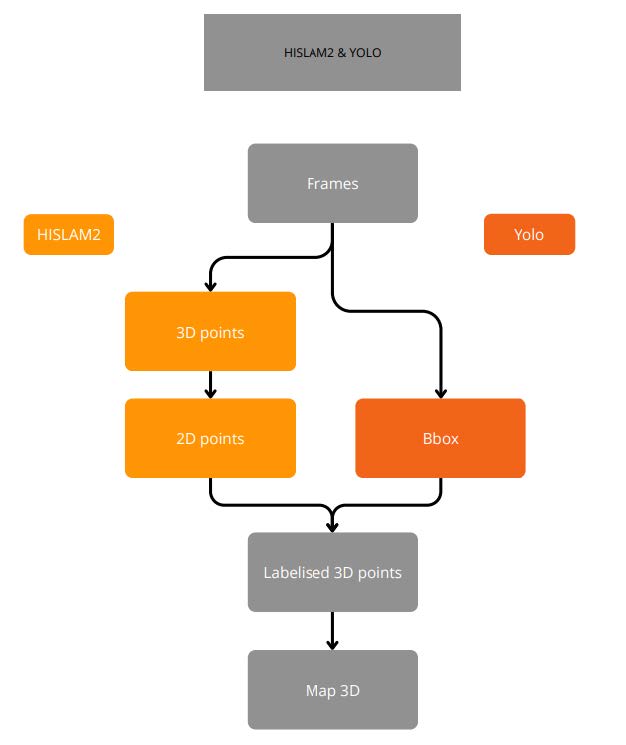
Le système parvient à générer des reconstructions 3D détaillées, même dans des conditions de lumière ou de mouvement complexes. La détection d’objets par Yolo fonctionne mais la fusion présente encore des limites adressables.

Des améliorations restent possibles, notamment en ce qui concerne la gestion des mouvements rapides de caméra, la précision de l’échelle réelle dans les reconstructions et la précision de la représentation 3D de la détection sémantique. Malgré cela, l’intégration de SLAM et de détection d’objets démontre une forte valeur ajoutée et ouvre la voie à de nombreuses applications futures.
Conclusion
Find Your Way illustre de manière concrète comment l’intelligence artificielle multimodale peut répondre à des besoins réels. Au coeur du projet, l’objectif est de faciliter la navigation et la compréhension de l’environnement pour les personnes malvoyantes ou en difficulté de repérage. En combinant plusieurs modules avancés comme la détection d’objets avec YOLOv11, raisonnement visuel via MiniCPM, et cartographie 3D grâce à SLAM. FYW permet une perception fine de l’environnement et une interaction naturelle avec celui-ci.
L’utilisateur peut interroger la scène devant lui à l’aide de questions contextuelles, mais aussi être guidé de manière dynamique pour atteindre un lieu précis dans son champ de vision. L’accent est mis sur des instructions claires, adaptées à son environnement, afin de garantir un déplacement fluide et sécurisé.
En somme, Find Your Way propose une expérience d’assistance intelligente qui place l’utilisateur au centre, en lui offrant les moyens d’interagir avec son environnement de manière autonome et confiante.
Pour aller plus loin
Vous avez aimé cet article ? Voici quelques ressources pour approfondir :
- MiniCPM-V: A GPT-4V Level MLLM on Your Phone
- HI-SLAM2: Geometry-Aware Gaussian SLAM for Fast Monocular Scene Reconstruction
- YOLOV11: AN OVERVIEW OF THE KEY ARCHITECTURAL ENHANCEMENTS
