


L’intelligence artificielle est de plus en plus performante. Cette tendance augmente cependant son coût énergétique à mesure que les modèles deviennent complexes et volumineux. A cette approche de la performance par la puissance de calcul s’oppose une intelligence artificielle plus verte et plus légère : l’IA frugale. Comment celle-ci peut-elle être mise en œuvre ?
Les axes de l’intelligence artificielle frugale
L’idée de l’IA frugale est de sacrifier un peu de précision pour obtenir un modèle bien moins énergivore et, éventuellement, intégrable dans un système embarqué.
L’approche frugale peut jouer sur quatre axes :
- La donnée d’entrainement pour accélérer l’apprentissage du modèle et limiter les itérations,
- L’architecture pour faire autant avec moins de ressources,
- L’entrainement par la mise en œuvre de technique spécifiques,
- L’inférence en compressant des modèles déjà entrainés
Chacun de ces axes propose de nombreuses techniques pour rendre le modèle moins énergivore. Nous nous sommes focalisés sur deux d’entre-elles : 1) la distillation de connaissances qui permet de transférer des capacités d’inférence d’un modèle complexe sur un modèle plus léger et 2) la recherche automatique d’architecture.
L’innovation de notre approche est de combiner ces deux techniques.
La distillation de connaissance
La distillation de connaissance transfère la “connaissance” d’un modèle lourd dans un modèle plus léger. Par analogie, on parle de modèle professeur et étudiant.
Les approches standards d’entrainement utilisent les erreurs d’un modèle pour le guider, par itérations successives, vers de meilleures prédictions. Classiquement, ces erreurs sont une mesure de l’écart entre la prédiction du modèle et la réponse attendue.
La distillation de connaissance complète cette mesure par l’erreur de distillation : l’écart entre la prédiction du modèle étudiant et la prédiction du modèle professeur. De cette façon, le professeur contribue à l’entrainement du modèle étudiant.
Plus spécifiquement, pour une tâche de classification à 3 catégories, on va regarder comment l’étudiant s’écarte des probabilités estimées par le professeur pour chacune des 3 catégories.
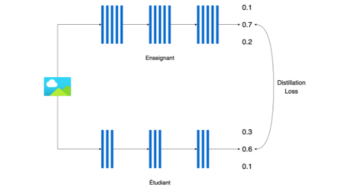
Illustration de l’erreur de distillation (source : Thomas Margnac)
La première partie de notre projet a été de faire une analyse de sensibilité des techniques de distillation sur une tâche de classification du jeu de données CIFAR-10 (60 000 images et 10 classes). Nous avons constaté que le paramètre le plus délicat à contrôler était l’architecture du modèle étudiant.
Ceci nous a amené à envisager l’utilisation de techniques de recherche automatique d’architecture pour définir celle du modèle étudiant avec l’espoir de l’optimiser pour un entrainement par distillation de connaissance.
Principe de la distillation de connaissance (source : Thomas Margnac)
Comment fabriquer le meilleur étudiant possible ?
La recherche automatique d’architecture
La recherche automatique d’architecture est un domaine du Deep Learning qui se développe depuis quelques années avec comme vision d’industrialiser la conception d’architecture de réseaux de neurones. Elle est plus connue sous l’acronyme NAS pour Neural Architecture Search.
L’approche naïve est de tester des architectures de façon très peu supervisée en les créant quasiment au hasard par assemblage d’opérations piochées aléatoirement dans un ensemble de d’opérations défini à l’avance par le concepteur.
L’approche plus avancée consiste à proposer une architecture initiale en plusieurs couches dans laquelle les sorties de chaque couche sont traitées par toutes les opérations disponibles pondérées par un même poids. Lors de la phase d’entrainement, l’algorithme ajuste ces poids. Au final, seules les opérations dont le poids est significatif sont retenues dans l’architecture. Ce mécanisme est illustré sur l’image ci-dessous.
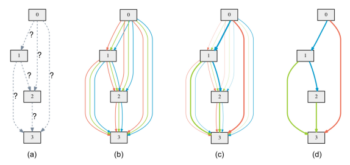
Un aperçu du NAS avancée (source : [1])
(a) Les opérations entre couches sont initialement inconnues. (b) Toutes les opérations disponibles traitent la sortie de chaque couche avec le même poids. (c) L’algorithme optimise les poids des opérations pour minimiser l’erreur durant l’entrainement. (d) L’algorithme ne retient que les opérations significatives.
La deuxième partie de notre projet a donc été la prise en main de ces techniques de NAS.
Générer un étudiant parfait
Finalement, la troisième partie du projet a été l’intégration des deux techniques dans le but de contraindre la recherche d’architecture par la distillation. On peut reformuler cela en disant qu’on a cherché à adapter l’étudiant aux méthodes du professeur.
Pour cela, nous avons modifié la mesure de l’erreur de l’étudiant pour lui donner la forme de celle utilisée en distillation.
Dans cette approche, l’entrainement a donc deux objectifs distincts mais complémentaires. Il faut d’une part déterminer les poids des différentes opérations dont on dispose ; c’est le NAS. Il faut d’autre part déterminer les paramètres de ces opérations ; c’est l’entrainement classique des modèles de Deep Learning. Ces deux parties sont effectuées sous la supervision du professeur mise en œuvre, comme on l’a vu, par des mesures d’erreur appropriées. Elles doivent être séquencées de façon judicieuse pour être efficace.
Conclusion
Nous avons livré un modèle fonctionnel qui met en œuvre les concepts exposés dans ce post et nous avons obtenus de premiers résultats encourageants qui confirment l’intérêt de l’approche. La prochaine étape est d’explorer plus finement ses performances et d’affiner la technique.
Références
[1]: DARTS: Differentiable Architecture Search / https://arxiv.org/abs/1806.09055
