


L’IA devient omniprésente avec des connaissances toujours plus larges et plus précises. Avec cette amélioration constante de l’IA, une nouvelle problématique émerge : l’Unlearning, ou l’Oubli en français.
Les modèles d’IA sont capables d’apprendre rapidement des quantités massives d’informations, mais qu’arrive-t-il lorsque ces données ne doivent pas être utilisées ? Cette question, jusque-là secondaire, est, aujourd’hui, devenue prioritaire (problèmes : éthiques et réglementaires).
Qu’est ce que le désapprentissage ?
Le désapprentissage (ou machine unlearning), consiste à faire en sorte qu’une IA “oublie” des données qu’elle a utilisées, comme si elle ne les avait jamais vues. Cela peut concerner des données personnelles, sensibles, ou obsolètes.
Voici un schéma explicatif pour un oubli d’images :
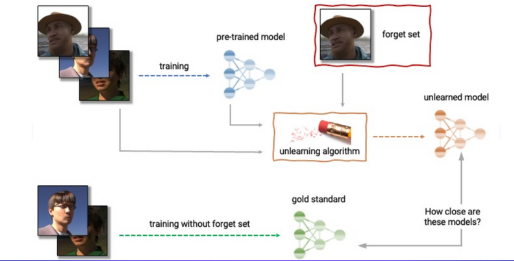
Illustration d’un cas concret
Nous avons voulu savoir ce que ChatGPT pouvait bien penser d’un camarade, membre du projet Alexandre Autrive. Nous lui avons soumis cette question :

Voici une réponse simple dont la source est LinkedIn, rien de problématique.

Cet exemple illustre bien l’intérêt du Unlearning : lorsqu’un modèle poursuit automatiquement en générant une adresse — potentiellement sensible — cela révèle qu’il a mémorisé des données qu’il ne devrait pas. Le Unlearning permet justement d’effacer ce type d’informations de manière ciblée.
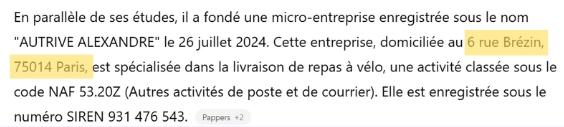
Alexandre pourrait bénéficier de son droit à l’oubli et profiter du Unlearning pour éliminer cette information.
Il existe beaucoup d’autres cas dans un contexte académique ou industriel, comme le fait de pouvoir éliminer l’influence de données erronées ou biaisées en évitant un réentraînement total du modèle. Un entraînement complet implique un coût énergétique énorme et une perte de temps significative que le Unlearning permet d’éviter.
De nombreux défis sont liés au Unlearning, notamment la quantification de l’oubli, il n’existe pas encore beaucoup de métriques capables de mesurer l’oubli. Au cœur du Unlearning se trouve le dilemme oubli-performance. Si on force un oubli total et “parfait” on risque de compromettre la qualité globale des réponses du modèle. Inversement, si l’on privilégie à tout prix la pertinence des réponses, cela peut limiter le seuil tolérable d’oubli.
Un objectif commun, mais deux visions différentes…
Dans notre projet de désapprentissage nous avons exploré deux approches :
GRUN, son fonctionnement est basé sur la modification directe des poids internes au modèle. Cette méthode permet un oubli fort et permanent.
PFA (Prompt Filtering Agent). Cette solution agit en amont et en aval du modèle d’IA. PFA va filtrer la question de l’utilisateur envoyée au modèle pour voir si elle est en lien avec des données à oublier. De plus elle utilise d’autres IA comme juges pour évaluer et noter les réponses générées. Cela permet de vérifier l’absence de données à oublier dans la réponse avant qu’elle soit retournée à l’utilisateur.

GRUN : le contrôleur d’identité
Au cœur du Unlearning se trouve le dilemme performance/oubli. Si on applique des transformations trop importantes au modèle pour s’assurer de son oubli, on risque de compromettre ses souvenirs sur d’autres sujets que l’on ne souhaitait pas effacer. A l’inverse si l’opération que l’on applique est trop douce, l’oubli peut s’avérer imparfait et l’objectif du Unlearning n’est pas rempli.
Pour cette raison, nous avons choisi la solution GRUN (Gated Representation UNlearning) qui offre une approche intéressante. Il s’agit d’une intervention. La solution va se greffer à l’intérieur du modèle entre deux couches, il va intercepter les informations transmises d’une couche à la suivante puis les modifier en cas de besoin avant de les transmettre à la suivante.
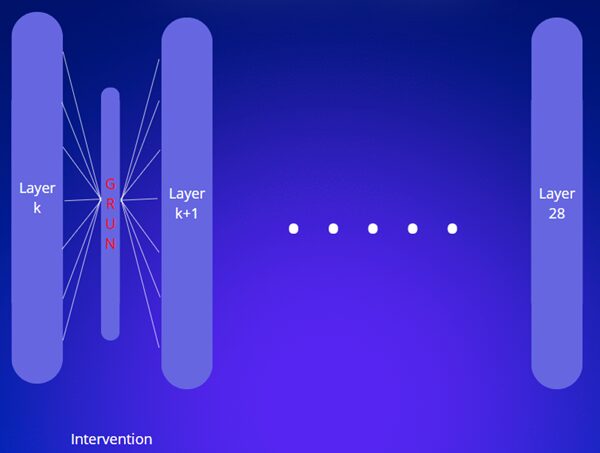
GRUN se décompose en deux blocs : la soft gate et le bloc ReFT.
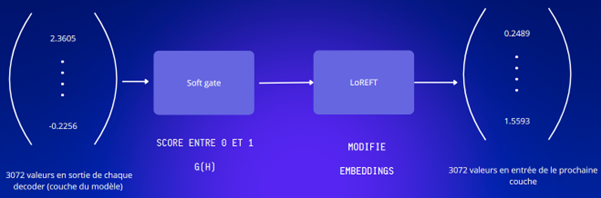
La soft gate : le bloc qui effectue un contrôle des informations en sortie d’une couche du modèle
Le bloc ReFT décide de les transformer ou non en fonction du résultat du contrôle.
Si les informations issues de la couche précédente ressemblent aux informations à oublier :
- La soft gate envoie un signal d’alerte pour prévenir le bloc suivant.
- Le bloc ReFT fait une transformation pour ne pas laisser passer les informations.
Inversement, si les informations ne correspondent pas aux éléments à oublier alors les informations peuvent circuler sans que le bloc ReFT ne les modifie.
Si on soumet au modèle des éléments à oublier, alors on souhaite que la soft gate s’active, le bloc ReFT transforme les informations envoyées aux couches suivantes pour que le modèle réponde des expressions similaires à la formule : “Je ne sais pas” ou “Je ne peux pas répondre”.
Pour revenir au dilemme initialement présenté, cette architecture permet d’obtenir un bon compromis en permettant au modèle d’avoir deux modes de fonctionnement. Un mode normal où le modèle agit comme s’il n’y avait pas d’intervention GRUN (soft gate pas activée) et donc la performance est conservée. Le deuxième mode est celui de l’oubli (soft gate activée) qui permet de correctement répondre à notre enjeu initial.
Résultats GRUN
Effacer des connaissances d’un modèle d’IA n’est pas trivial. Le Machine Unlearning est un domaine récent, il reste complexe de quantifier l’oubli tout en vérifiant que le reste du savoir est préservé. Nous avons donc sélectionné quatre métriques complémentaires répondant à ces deux exigences :
- ROUGE-L et Probability – mesure l’efficacité de l’oubli. ROUGE-L calcule la similarité entre la réponse générée par l’IA et la référence (si ces deux textes se ressemblent alors le score est élevé) ; plus le score baisse sur les contenus à supprimer, plus l’oubli est efficace.
- ROUGE-L retain et Truth Ratio – vérifie la conservation des connaissances à garder. Le premier observe si la qualité des réponses reste stable, le second mesure la proportion de réponses factuellement correctes après unlearning.
- Sélectivité des gates (spécifique à l’architecture GRUN) – pour s’assurer que les gates ciblent exclusivement les informations à oublier sans détériorer les autres.
En combinant ces indicateurs – diminution de ROUGE-L et de probabilité sur les données oubliées, stabilité de ROUGE-L retain et du truth ratio sur les données conservées, et sélectivité des gates – nous obtenons une évaluation robuste qui répond aux questions : le modèle a-t-il vraiment oublié ce que l’on voulait supprimer, et a-t-il conservé le reste de son savoir ?
Présentation des résultats finaux
A la fin de nos expérimentations,
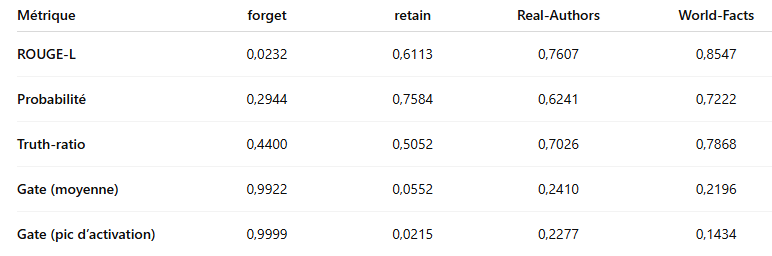
GRUN fait presque totalement disparaître l’information à oublier. En ciblant 10 % des données, le score ROUGE‑L chute de 0,65 à 0,03 et la probabilité de réponse correcte passe de 0,78 à 0,25.
Cet oubli est significatif, la performance sur les contenus à conserver reste satisfaisante, avec un ROUGE‑L d’environ 0,51 et un truth‑ratio supérieur à 0,49, traduisant une dégradation modérée. Le gate linéaire, quant à lui, s’active à plus de 0,99 pour les prompts à oublier tout en restant en dessous de 0,30 pour ceux à retenir, attestant d’un ciblage très précis.
Malgré ces résultats encourageants, certaines limites subsistent. L’efficacité de l’oubli dépend fortement du choix des couches où GRUN est appliqué, et l’ajustement du mécanisme de gating nécessite un calibrage minutieux. Nos tests ont été effectués sur une petite quantité de données et ont nécessité un temps d’apprentissage important, et il reste à voir s’il peut être utilisé sur un plus large éventail de données.
PFA : La méthode soft, sans toucher au modèle
Ce POC s’appuie sur les travaux de Guardrail Baselines for Unlearning in LLMs qui dit : “Simple guardrail based approaches such as prompting and filtering can achieve unlearning results comparable to finetuning”. Pour comprendre cette phrase, il faut savoir ce que veulent dire les termes “Prompting” et “Filtering”.
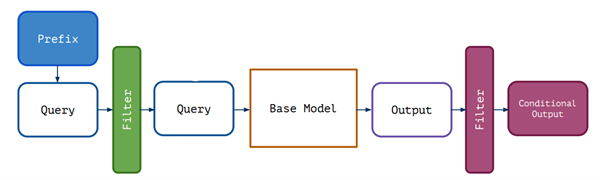
Prompting : Il s’agit de la partie qui précède le modèle (Base Model sur le schéma). Pour le comprendre facilement, il est par exemple possible d’ajouter une phrase au début de la requête pour forcer le modèle à “oublier” une information. Il est par exemple possible d’ajouter au prompt : « Vous êtes une IA censée avoir oublié Leonardo DiCaprio. Répondez comme si vous ignoriez son existence. » Les LLMs sont suffisamment puissants pour que ce genre de consigne ait un effet notable.
Filtering : Cette méthode correspond à la partie qui vient après le modèle. Cela consiste à analyser la réponse du modèle, et à la filtrer si elle contient une information à oublier. Cela peut se faire par détection de mots-clés, classifieur binaire ou même en demandant au modèle : « Cette réponse contient-elle des infos sur Leonardo DiCaprio ? Oui ou Non. »
Nous avons donc voulu tester cela en utilisant les travaux de l’article [2406.07933] Large Language Model Unlearning via Embedding-Corrupted Prompts pour la partie prompting et en s’inspirant des travaux de [2502.00406] ALU: Agentic LLM Unlearning pour la partie Filtering. Notre projet utilise 4 agents afin de réaliser le unlearning. Deux agents sont consacrés au prompting et deux autres agents sont consacrés au filtering.
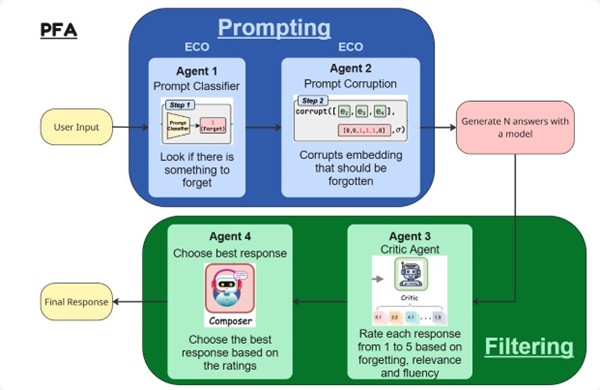
Pour le prompting :
La méthode ECO est employée et consiste à corrompre sélectivement les embeddings (représentations vectorielles des tokens) lorsque l’utilisateur soumet une requête contenant des informations désignées pour être oubliées. Cette corruption ne s’applique pas au texte brut, mais directement aux vecteurs.
Un agent de Classification (agent 1) identifie les entrées nécessitant cette altération, un agent de Corruption (agent 2) modifie alors les embeddings concernés, empêchant ainsi le modèle de traiter correctement les informations ciblées.
Par exemple si le prompt est “Qui est Harry Potter ?” et que l’on veut faire oublier Harry Potter, l’agent 1 va classifier le prompt comme “à corrompre” tandis que l’agent 2 va corrompre les embeddings correspondant aux mots “Harry Potter”.
Pour le filtering :
La méthode ALU mobilise aussi deux agents pour renforcer la fiabilité des réponses.
L’agent Critic (agent 3) évalue les réponses selon trois critères : le niveau d’oubli (efficacité, utilité et formulation de l’unlearning)
L’agent de Décision (agent 4) choisit la meilleure réponse parmi plusieurs propositions, en s’appuyant sur ces évaluations. Ce processus permet de limiter les erreurs potentielles pouvant survenir lors de la phase de prompting.
Résultats PFA
Quand on demande à une intelligence artificielle d’oublier certaines informations, il faut vérifier deux choses :
- A-t-elle vraiment oublié ce qu’on voulait supprimer ?
- A-t-elle conservé le reste de son savoir ?
Pour cela, l’évaluation repose sur l’un des indicateurs clés de GRUN : le ROUGE-L score.
Nous avons aussi défini deux datasets:
- Retain90 : contient les informations à conserver.
- Forget10 : contient les informations à oublier.
Résultats avec la méthode ECO
La méthode ECO, après quelques ajustements pour éviter un apprentissage biaisé, donne :

On observe une très bonne conservation du savoir général et un oubli partiel seulement.
Résultats avec la méthode PFA

On observe une légère baisse de la mémoire globale et un oubli plus efficace.
Nos résultats montrent un compromis : mieux l’IA oublie ce qu’on lui demande, plus elle risque de perdre d’autres connaissances. Même si ce compromis reste très limité : l’oubli est fort et ciblé et la majorité du savoir est conservée, dans certains champs d’application une perte sur les informations à conserver n’est pas envisageable.
Conclusion PFA/Grun
Dans le cadre de cette étude comparative entre les méthodes d’Unlearning PFA et GRUN, les résultats mettent en évidence des profils complémentaires. La méthode GRUN se distingue par une excellente capacité à effacer l’information ciblée, Cette efficacité est renforcée par des valeurs élevées sur les métriques “Gate”. En revanche, cette approche se fait au détriment de la conservation des connaissances utiles, avec une baisse notable de performance sur les corpus de retain, notamment un score ROUGE-L de 0.6113.
À l’inverse, PFA se montre plus équilibrée : elle parvient à mieux préserver les connaissances générales, tout en maintenant de bonnes performances sur des métriques de vérité, mais ces effets sur la capacité à oublier les infos ciblées sont moins performantes.
En résumé, le choix entre GRUN et PFA doit se faire en fonction des priorités du cas d’usage : GRUN est à privilégier si l’oubli complet est l’objectif principal (données sensibles, droit à l’oubli), tandis que PFA est plus adaptée lorsqu’il est essentiel de préserver au maximum les connaissances utiles du modèle (secteurs scientifiques, santé, éducation).
À l’avenir, ces méthodes pourraient jouer un rôle majeur dans les domaines soumis à des régulations strictes (RGPD, …), ou nécessitant des modèles capables d’évoluer sans être totalement réentraînés. Le désapprentissage ciblé ouvre la voie à des systèmes plus responsables, adaptables et éthiques.
