


Au début de tout projet de recherche ou de développement, il est essentiel de se pencher sur les travaux préexistants en lien avec le sujet étudié. Cette phase s’appelle l’état de l’art. Elle a pour but de synthétiser l’ensemble des connaissances disponibles dans les articles scientifiques relatifs à une problématique afin de poser des bases solides pour le projet.
Cependant, avec l’explosion du volume des publications scientifiques, la réalisation de l’état de l’art devient une tâche de plus en plus complexe et chronophage.
L’objectif de cet article est de comprendre comment automatiser cette tâche, traditionnellement réalisée manuellement, en exploitant les dernières techniques de traitement automatique du langage (TAL, ou NLP en anglais).
Prioriser des articles de haute qualité
Lorsque l’on recherche des articles scientifiques sur un sujet donné, il peut s’avérer difficile de faire le tri parmi la quantité d’informations. Pour sélectionner les articles les plus pertinents, il faut alors les lire un par un et les analyser, ce qui peut rapidement devenir un travail long et fastidieux. C’est pourquoi nous avons ici développé une approche qui repose sur un système de notation rigoureux de la qualité d’un article scientifique en fonction de plusieurs indicateurs déterminés grâce à notre propre expérience.
Nous récupérons différents critères pouvant servir pour évaluer la qualité d’un article, que ce soient des critères évaluant le contenu de l’article (s’il possède un code source, s’il mentionne ses sources, …), mais également le contexte de sa publication (la réputation des auteurs, la date de publication, …).
Pour ce faire, nous avons utilisé différents outils :
- Scholarly, qui permet de récupérer diverses informations sur les publications ou les auteurs directement sur Google Scholar.
- Marker pdf, pour pouvoir convertir les pdf récupérés en fichier markdown pour faciliter l’extraction de certaines informations.
- Paper with code, pour pouvoir vérifier la disponibilité du code source ou du dataset utilisé par les chercheurs grâce au titre de l’article.
- Fitz pour pouvoir extraire les images de l’article et ainsi les identifier pour vérifier la présence de schéma de l’architecture, de graphiques ou encore de benchmark.
Puis nous attribuons, pour chacun de ces critères, une note sur une échelle commune.
Mais nous ne nous arrêtons pas là : chaque indicateur a un poids différent selon son importance réelle, ce qui signifie que nous appliquons une pondération pour refléter la véritable valeur de chaque aspect vis-à-vis des autres.
Ainsi, chaque article obtient un score qui correspond à la somme de chaque valeur cumulée. Si ce dernier est suffisamment élevé, l’article associé sera considéré comme de bonne qualité. Ce processus transparent permet, entre autres, de mieux comprendre pourquoi certains articles sont plus fiables que d’autres.
Les articles peuvent être ainsi triés en fonction de leur score global obtenu et nous pouvons avoir une vision de la validation de chaque critère pour nous aider lors de la sélection des papiers les plus pertinents.
Voici un exemple de score obtenu pour un article :

On peut ici voir entre parenthèse le score global obtenu, les articles sont ainsi triés du plus haut score au moins élevé. On peut également voir le détail de chaque critère avec un signe validé si l’article le possède et un signe croix à l’inverse, ce qui nous permet ainsi de calculer le total.
Regrouper intelligemment les connaissances
Une fois le premier tri effectué, il nous reste à organiser l’ensemble des articles sélectionnés. Lorsqu’un sujet porte sur un thème assez général, il est assez commun d’avoir une grande quantité d’articles qui peuvent porter sur des aspects plus précis du sujet. Afin de mieux comprendre notre corpus d’articles, il est nécessaire de les trier et d’essayer de les regrouper dans différents sous-thèmes plus spécifiques. Cette étape permet à la fois de mieux comprendre notre corpus d’articles mais également d’identifier les thèmes les plus pertinents à utiliser pour créer notre état de l’art.
La création de ces sous-thèmes au sein de notre sujet de recherche peut également amener à mieux cerner la direction dans laquelle creuser pour la suite du projet. Elle permet également d’écarter les sous-thèmes n’ayant pas de rapport direct avec le contexte de notre projet.
Afin d’effectuer cette opération, nous avons choisi d’utiliser BERTopic.
Il s’agit d’un framework de topic modeling qui se base sur l’utilisation de BERT un modèle de traitement de langage large déjà entrainé. BERTopic utilise sentence BERT pour créer les embeddings des différents articles puis utilise une méthode de réduction de dimension UMAP avant de clusteriser les articles et de créer une représentation des différents clusters en utilisant une méthode c-TF-IDF qui compte la fréquence d’apparition des mots dans les documents afin de déterminer quels sont les mots qui représentent le mieux le sous-thème.
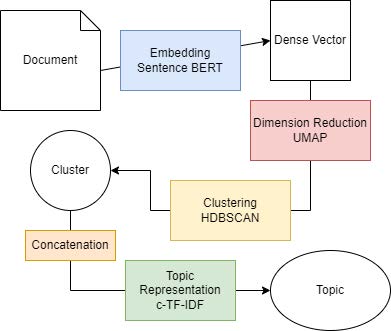
BERTopic nous permet de créer plusieurs sous-thèmes automatiquement à partir de notre corpus de documents sélectionnés. De plus, le modèle est rapide et modulable.
Nous avons conduit une phase de test afin d’adapter au mieux le modèle au besoin de notre projet et il en est ressorti que le modèle de base fonctionnait déjà bien mais en réglant le paramétrage du clustering nous avons pu améliorer la répartition des articles dans les sous-thèmes pour la rendre plus pertinentes et qu’elle s’apparente plus à une répartition humaine.
L’analyse des résultats obtenus après la classification des documents est une étape clé de la phase de l’état de l’art puisqu’elle permet d’identifier les différentes parties pertinentes pour la réalisation du projet.

Générez des résumés efficaces : accédez à l’essentiels en un clin d’oeil !
Maintenant, nous avons une très grande quantité d’articles qu’il faut lire plusieurs fois afin de bien comprendre les solutions apportées par ces articles. Mais la lecture de chacun d’entre eux est très longue et fastidieuse. Nous risquons de rater des informations primordiales pour la compréhension de l’article si nous nous restreignons à l’abstract. Il nous faudrait un moyen de rapidement savoir de quoi parle l’article sans avoir à le lire entièrement.
C’est à ce moment-là que notre application vient apporter toute sa valeur ajoutée ! En effet, elle permet de faire gagner beaucoup de temps sur cette étape en générant de courts résumés pour chaque article. Ces résumés sont générés grâce à un modèle fonctionnant en deux étapes.
Dans un premier temps, nous avons une étape de sélection du contenu. Nous allons identifier et récupérer les phrases les plus pertinentes de l’articles tout en ignorant les informations superflues afin de construire un résumé allant droit au but et complet. Ces phrases sont récupérées en comparant chaque phrase du texte avec un résumé de référence, dans le cas d’un article scientifique, le résumé de référence est l’abstract du document. La comparaison va s’effectuer grâce à la métrique ROUGE-1 qui est une métrique qui compare la similarité des mots individuels entre la phrase et le résumé de référence.
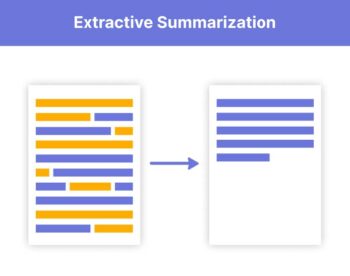
Chaque phrase obtient alors un score et les phrases avec le meilleur score seront gardées. Ce type de résumé conserve les phrases du document de base, on appelle cela un résumé extractif.
Ensuite, dans un second temps, nous allons créer un nouveau texte de toutes pièces, mentionnant toutes les informations extraites précédemment. Ces résumés sont générés grâce à un modèle de traitement de langage naturel, basé sur l’architecture des transformers possédant un système d’attention particulière. Ce modèle est une version fine-tune du modèle BART, ainsi l’entraînement se fait rapidement et est spécifique à la tâche de résumé de documents longs. Par ailleurs, au lieu de calculer la valeur d’attention qui lie chaque token avec tous les tokens du document, nous comparons seulement avec les tokens adjacents.
C’est ce que nous appelons la window attention. Cela permet de pouvoir réaliser un résumé d’un article d’une longueur conséquente.
La combinaison de ces deux méthodes garantit une compréhension globale et précise de l’article, même pour les sections situées à la fin du document, et ce, quelle que soit la longueur du texte initiale. Voici des exemples de résumés générés par notre modèle directement depuis notre application.

En définitive, notre application vous permet de découvrir les informations essentielles d’un article sans avoir à le lire en entier, en les condensant en un très court paragraphe. En quelques secondes seulement, vous aurez accès à un résumé précis et facile à comprendre, vous aidant ainsi à déterminer rapidement quels articles sont les plus pertinents pour votre projet.
Conclusion
Notre solution peut donc vous permettre de gagner un temps précieux dans toutes vos recherches ! Plus besoin de passer des heures à lire des articles qui ne vous serviront pas : passez simplement votre temps à lire les résumés d’écrits qui vont vous intéresser.
Selon nos estimations, un groupe de 5 personnes réalisant un état de l’art, comme celui que nous avons dû faire pourrait passer de 2 mois à 3 semaines pour une sélection d’une trentaine d’articles dans n’importe quel sujet en lien avec leur projet !
Il ne vous restera plus qu’à lire les résumés des documents qui vous intéressent et à analyser les résultats de notre application. Notre solution se charge même de vous fournir le document récapitulatif prérempli à fournir à la fin de vos recherches sur l’existant !
En adoptant notre outil, non seulement vous optimisez votre temps, mais vous améliorez également la qualité de vos travaux en ayant un état de l’art complet, couvrant toutes les facettes du domaine recherché. Notre application utilise des modèles avancés pour
s’assurer que les articles sélectionnés soient de qualité, que les résumés fournis soient pertinents et exhaustifs, et que les documents soient bien ordonnés par thèmes précis. De plus, notre interface conviviale est très ludique et facile d’utilisation. Utiliser notre solution permettra à vos recherches d’être plus efficaces et rigoureuses !
