


Introduction
L’intelligence artificielle est au cœur des débats concernant sa consommation d’énergie et son danger pour notre planète. En effet un entrainement de chatgpt3 correspond à 250 allers-retours Paris/New-York en avion soit 550 tonnes de CO2 rejetées.

Le frugal learning est une approche qui cherche à rendre l’intelligence artificielle plus accessible mais surtout plus durable en réduisant les ressources nécessaires à l’entraînement et à l’inférence des modèles. Avec l’augmentation des tailles de modèles, les techniques telles que la quantization, le pruning et la knowledge distillation sont essentielles pour garantir des performances optimales tout en minimisant les coûts et l’empreinte écologique.
1. Quantization avec la Méthode AWQ
Qu’est-ce que la Quantization?
La quantization est un processus qui réduit la précision des poids des modèles neuronaux, passant de 32 bits flottants à des représentations moins précises comme 8 bits ou même moins. Cela permet de réduire la taille du modèle et d’accélérer les calculs sans compromettre significativement les performances.
Méthode AWQ
La méthode AWQ (Asymmetric Weight Quantization) est une technique de quantization avancée qui permet une meilleure représentation des poids des réseaux neuronaux. Contrairement aux approches symétriques, AWQ utilise des plages de valeurs asymétriques pour chaque couche du réseau, ce qui permet une compression plus efficace et une réduction des erreurs de quantization.
Avantages de la Quantization
- Réduction de la taille du modèle : En utilisant moins de bits pour représenter les poids, la mémoire nécessaire pour stocker le modèle est réduite, ce qui permet de déployer des modèles sur des dispositifs à faible capacité de mémoire.
- Accélération des temps d’inférence : Les calculs sur des entiers sont plus rapides que ceux sur des flottants, ce qui réduit le temps nécessaire pour faire des prédictions.
- Moins de consommation d’énergie : Des modèles plus petits et des calculs plus rapides se traduisent par une réduction de la consommation d’énergie, ce qui est crucial pour les dispositifs embarqués et les applications mobiles.
Défis et Solutions
L’un des défis de la quantization est la perte de précision qui peut survenir lors de la réduction de la précision des poids. La méthode AWQ aborde ce problème en utilisant des plages de valeurs asymétriques, ce qui permet de maintenir une plus grande précision tout en bénéficiant des avantages de la quantization.
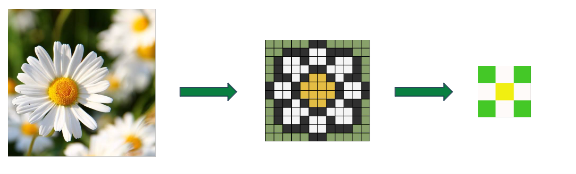
Float: 3.141517 Float: 3.14 Int: 3
Résultats
Nous verrons les résultats pour la combinaison du pruning et de la quantization par la suite étant donné que ces deux méthodes ont les mêmes objectifs : diminuer la taille du modèle tout en augmentant sa vitesse de génération de tokens.
2. Pruning avec la Méthode SparseGPT
Qu’est-ce que le Pruning?
Le pruning est une technique qui consiste à supprimer les poids non essentiels d’un réseau neuronal. En éliminant ces poids, le modèle devient plus petit et plus rapide, tout en maintenant une précision comparable à celle du modèle original.
Méthode SparseGPT
SparseGPT (Sparse Generalized Pruning Technique) est une méthode de pruning avancée qui identifie et élimine les poids redondants dans un réseau neuronal. Elle utilise des algorithmes d’optimisation pour sélectionner les poids à supprimer de manière à minimiser l’impact sur la performance du modèle. De plus cette méthode permet de ne pas avoir à refaire d’entrainement du modèle pour le pruner, ce qui implique donc un gain de ressources considérable.
Avantages du Pruning
- Réduction de la complexité du modèle : En éliminant les poids inutiles, le modèle devient plus simple et plus facile à comprendre et à gérer.
- Amélioration des temps d’entraînement et d’inférence : Moins de poids signifie moins de calculs, ce qui accélère l’entraînement et l’inférence.
- Moins de consommation de mémoire : Un modèle pruned nécessite moins de mémoire pour le stockage et les opérations, ce qui est bénéfique pour les déploiements sur des dispositifs à ressources limitées.
Défis et Solutions
Le pruning peut parfois entraîner une perte de performance si les poids critiques sont supprimés. La méthode SparseGPT utilise des algorithmes sophistiqués pour identifier et préserver les poids les plus importants, minimisant ainsi la perte de performance tout en maximisant la réduction de la taille du modèle.

Résultats
Voici nos résultats pour la combinaison du pruning et de la quantization, résumé dans un tableau de valeur :

On a donc divisé la taille des modèles par un peu plus de deux et augmenter leurs vitesses d’inférence dans chacun des cas.
3. Knowledge Distillation avec la Méthode TSLD Logit des Tokens
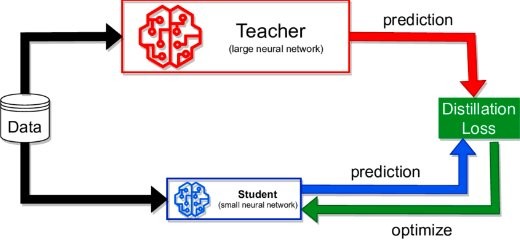
Qu’est-ce que la Knowledge Distillation?
La knowledge distillation est un processus par lequel un modèle de grande taille (le “teacher”) transfère ses connaissances à un modèle plus petit (le “student”). Ce transfert permet au modèle plus petit d’atteindre une performance similaire à celle du modèle plus grand tout en étant beaucoup plus léger.
Méthode TSLD Logit des Tokens
La méthode TSLD (Token-based Soft Logit Distillation) est une approche innovante de knowledge distillation qui se concentre sur les logits des tokens individuels dans le modèle teacher. En effet elle s’adapte à la confiance des tokens qu’elle soit haute ou faible. L’avantage de cette méthode et donc d’éviter un surapprentissage pour les tokens à haute confiance et améliore la limitation de la perte d’entropie croisée pour les tokens à faible confiance. En distillant ces informations spécifiques, le modèle student peut apprendre plus efficacement et rapidement, tout en conservant une précision élevée.
Avantages de la Knowledge Distillation
- Modèles plus petits et plus rapides : Le modèle student est beaucoup plus compact que le modèle teacher, ce qui permet un déploiement plus facile et rapide.
- Maintien de performances élevées : Malgré sa taille réduite, le modèle student peut approcher ou atteindre les performances du modèle teacher.
- Réduction des coûts de déploiement et d’inférence : Des modèles plus petits nécessitent moins de ressources pour le déploiement et l’inférence, ce qui réduit les coûts.
Défis et Solutions
L’un des défis de la knowledge distillation est de s’assurer que le modèle student capte suffisamment bien les connaissances du modèle teacher. La méthode TSLD Logit des Tokens se concentre sur les informations logit cruciales des tokens individuels, assurant une distillation plus précise et efficace.
Résultats
Concernant la knowledge distilation nous avons dû nous intéresser à la perplexité du modèle pour savoir si nous avions réussi, comme prévu, à obtenir un gain de performances du modèle après application de la knowledge distilation.
Nous avons réussi à obtenir une perplexité de 27.5 après application de la knowledge sur un modèle OPT-125m qui possède une perplexité de 30 initialement. Nous avons considéré que c’était un gain plutôt encourageant pour la suite de notre projet.
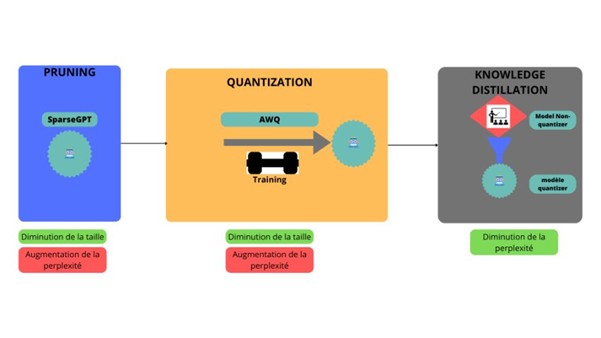
4. Combinaison des Méthodes : Ordre, Raisons et Avantages
Ordre de Combinaison des Méthodes
Pour maximiser les avantages des techniques de frugal learning, il est généralement recommandé de suivre cet ordre :
- Pruning
- Quantization
- Knowledge Distillation
Pourquoi cet ordre ?
Commencer par le pruning permet de simplifier le modèle en éliminant les poids redondants. Cela réduit la complexité du modèle, ce qui facilite les étapes suivantes.
Ensuite, la quantization est appliquée pour compresser davantage le modèle distillé, réduisant sa taille et améliorant la vitesse d’inférence sans compromettre la précision obtenue grâce aux étapes précédentes.
Enfin la knowledge distillation aide à transférer les connaissances du modèle original à un modèle plus petit, en assurant que le modèle simplifié conserve un haut niveau de performance.
Avantages de la Combinaison
- Réduction maximale de la taille et des ressources : En combinant ces techniques, on obtient une réduction significative de la taille du modèle et des ressources nécessaires à son entraînement et à son déploiement.
- Maintien de la performance : Le pruning simplifie le modèle sans trop de perte de précision et la quantization réduit encore plus la taille sans une perte notable de performance. Enfin la knowledge distillation permet de réentraîner le modèle avec les connaissances du teacher et donc de retrouver des performances similaires à celles du modèle teacher.
- Efficacité énergétique et rapidité : Les modèles ainsi optimisés consomment moins d’énergie et offrent des temps d’inférence plus rapides, ce qui est essentiel pour les applications en temps réel et les dispositifs embarqués.
- Accessibilité : Des modèles plus petits et plus efficaces sont plus faciles à déployer sur une variété de plateformes comme pour l’IOT, rendant l’IA accessible à un plus grand nombre d’utilisateurs et d’applications.
Résultats
Grâce à la combinaison de ces trois techniques nous avons obtenu des résultats très encourageant.
En effet, à partir d’un modèle OPT-125m nous avons réussi à diminuer sa taille par deux, tout en le rendant 1,5 fois plus rapide à générer des tokens et également à réduire son temps d’entrainement d’environ 50%. Nous avons cependant pu observer une perte de performance de maximum 10%, ce qui est largement suffisant pour la plupart des fonctionnalités d’un modèle.
Nous avons donc réussi à obtenir un modèle quasiment aussi performant que le modèle teacher, tout en réduisant sa consommation énergétique de façon considérable. Nous pouvons donc conclure que les techniques de frugal learning pourraient être l’avenir des IA, pour les rendre plus facile d’utilisation et surtout plus durable.
Applications Pratiques et Études de Cas
Applications de la Quantization
La quantization est particulièrement utile dans les applications où les ressources sont limitées, comme les dispositifs IoT, les smartphones, et les véhicules autonomes. Par exemple, dans les smartphones, les modèles de reconnaissance vocale quantifiés peuvent fonctionner plus rapidement et avec moins de consommation d’énergie, améliorant l’expérience utilisateur.
Applications du Pruning
Le pruning est souvent utilisé dans les réseaux neuronaux déployés sur des dispositifs embarqués et dans le cloud computing. Dans les dispositifs embarqués, il permet de déployer des modèles complexes sur des dispositifs avec des capacités de mémoire limitées. Dans le cloud, le pruning réduit les coûts de calcul et de stockage, rendant les services d’IA plus économiques.
Applications de la Knowledge Distillation
La knowledge distillation est largement utilisée dans les domaines de la vision par ordinateur et du traitement du langage naturel. Par exemple, dans les systèmes de reconnaissance d’images, un modèle distillé peut offrir une performance de pointe tout en étant assez petit pour fonctionner sur des dispositifs mobiles. De même, dans les applications de traitement du langage naturel, la distillation permet de déployer des modèles de compréhension du langage plus rapides et plus légers sans sacrifier la précision.
Conclusion
Le frugal learning, avec ses techniques de quantization, pruning et knowledge distillation, offre des solutions puissantes pour rendre l’intelligence artificielle plus efficace et durable. Ces méthodes permettent de réduire les ressources nécessaires tout en maintenant des performances élevées, ce qui est crucial dans un contexte où la demande pour des modèles d’IA plus rapides et plus écologiques ne cessede croître. Adopter ces techniques peut non seulement améliorer l’accessibilité de l’IA mais aussi contribuer à la réduction de son impact environnemental.
En explorant et en mettant en œuvre ces méthodes, les chercheurs et les ingénieurs peuvent faire progresser l’état de l’art en matière de frugal learning et offrir des solutions innovantes pour les défis futurs de l’IA.
En somme, la quantization, le pruning et la knowledge distillation sont des outils essentiels dans l’arsenal du frugal learning. Ces techniques non seulement réduisent la taille et la complexité des modèles, mais elles permettent aussi de maintenir, voire d’améliorer, leurs performances. En mettant en œuvre ces méthodes, nous pouvons faire un pas de plus vers une IA plus durable et accessible, tout en repoussant les limites de ce que ces technologies peuvent accomplir.