

")
Invisibles pour la plupart d’entre nous, les récifs coralliens jouent pourtant un rôle crucial dans l’équilibre de nos océans. Et si l’IA pouvait les sauver ?
Face à l’effondrement accéléré de la biodiversité mondiale, l’IA joue un rôle clé dans la protection de l’environnement. Dans le cas des récifs coralliens, qui comptent parmi les écosystèmes les plus riches et les plus menacés de la planète, l’IA offre des perspectives concrètes pour améliorer leur surveillance.
Cet article présente une solution basée sur l’IA pour identifier automatiquement les genres et espèces de coraux, évaluer leur état de santé et mesurer leur taux de blanchiment. Ce projet s’inscrit dans l’initiative de Science4Reefs, qui développe des outils pour mieux suivre la santé des récifs.
Pourquoi les coraux sont essentiels et pourquoi leur disparition nous concerne tous ? Qu’est-ce que le blanchissement corallien ?
Les récifs coralliens ne couvrent que 0,2 % des océans, mais ils abritent environ 25 % de la biodiversité marine. Ces récifs offrent un habitat, une zone de reproduction et une source de nourriture à des milliers d’organismes marins (poisson, mollusques, crustacés, …). Les coraux protègent les littoraux contre l’érosion en atténuant la force des vagues, et soutiennent les activités économiques de millions de personnes dans le monde, notamment par la pêche et le tourisme. Le tourisme lié aux coraux rapporte environ 35 milliards de dollars à l’économie mondiale.
Le blanchissement corallien est un phénomène de stress aigu subi par les coraux, généralement provoqué par une élévation de la température de l’eau. En réaction à ce stress, le corail expulse ses microalgues symbiotiques (zooxanthelles) qui lui fournissent sa couleur et surtout l’essentiel de ses nutriments. Privé de cette symbiose, le corail blanchit et devient plus vulnérable aux maladies, à la prédation et à la mort. Lorsque ces épisodes sont fréquents ou prolongés (comme au cours des dernières décennies), les coraux n’ont pas le temps de se régénérer, ce qui entraîne une dégradation irréversible des récifs.
Localisation et extraction du corail dans l’image : Segmentation
La segmentation est une étape clé de notre pipeline. Elle permet d’isoler les zones contenant du corail tout en excluant les éléments non pertinents (sable, poissons, roches). Cette sélection évite des erreurs dans l’analyse, comme confondre un fond clair avec un corail blanchi. Elle facilite également la classification des espèces en recentrant les modèles sur les seules structures biologiques pertinentes.
Notre approche repose sur deux méthodes : Mask R-CNN pour la détection automatique des formes coralliennes, et la superpixellisation (méthode de segmentation basée sur l’algorithme SLIC) pour affiner les contours et limiter le bruit.
Génération et optimisation des masques
L’utilisation de Mask R-CNN a posé plusieurs défis, notamment une précision insuffisante des masques générés, bien que les détections par boîtes englobantes soient satisfaisantes.
Problème de résolution
Les masques prédictifs de Mask R-CNN sont générés en 28×28 pixels, ce qui limite leur précision, notamment pour les structures complexes du corail. Pour améliorer cela, nous avons appliqué un upsampling à 56×56 pixels, doublant ainsi la définition spatiale des masques.
Normalisation et contraste
Les probabilités associées aux pixels “coral” étaient souvent plus faibles que celles du “background”. Pour y remédier, un post-traitement a été mis en place :
– Normalisation : Division de chaque valeur de pixel par la valeur maximale du masque, ramenant toutes les probabilités dans l’intervalle [0,1]>.
– Application d’un coefficient de contraste : Utilisation de la transformation 𝑉𝑐=𝑉𝑝15 afin de renforcer la séparation entre les zones de corail et l’arrière-plan où 𝑉𝑐 est la valeur contrastée, 𝑉𝑝 la valeur précédente.
– Seuillage adaptatif : Application d’un seuil à 0.05 pour éliminer les faibles valeurs parasites tout en conservant les régions structurales.
Détermination du seuil optimal par analyse statistique
Pour automatiser la binarisation, nous avons évalué 25 images représentatives et mesuré les scores de précision, rappel et F1-score en fonction du seuil appliqué. Le score F1 a été utilisé comme critère d’optimisation :
F₁ = 2 × (Précision × Rappel) / (Précision + Rappel)
Nous avons retenu un seuil conservatif correspondant au premier quartile de la distribution des meilleurs seuils (Q₁ = 0.65), ce qui favorise une couverture maximale des coraux.
Affinage avec superpixellisation (SLIC)
Pour compenser les limites des masques R-CNN, nous avons intégré un algorithme de superpixellisation SLIC, qui améliore la délimitation des contours. Cette approche hybride combine :
– Détection globale avec Mask R-CNN
– Affinage local via SLIC pour isoler les zones effectivement biologiques
Ce système agit comme un filtre intelligent, conservant uniquement les régions utiles pour les étapes de classification et d’analyse.
Comparaison et choix des algorithmes
Une comparaison entre SLIC, Quickshift et Felzenszwalb-Huttenlocher a montré que SLIC est le plus adapté à notre cas.

Figure 1 : LoU fonction du nombre de segments et du seuil
L’optimisation des paramètres (seuil et nombre de segments) a été réalisée par maximisation de l’IoU (Intersection over Union) sur le dataset de validation. L’algorithme d’attribution des superpixels applique une règle de décision binaire : si plus de 70% des pixels d’un superpixel sont classifiés “coral” par le masque R-CNN, l’intégralité du superpixel est conservée. Cette approche permet un raffinement des contours tout en préservant la cohérence régionale.
Validation et généralisation
L’analyse statistique sur 25 images a permis d’établir des paramètres fixes généralisables :
– Seuil superpixellisation : 0.6 (premier quartile)
– Nombre de segments : 70 (médiane après élimination des outliers)
Cette approche garantit un fonctionnement automatisé sans intervention utilisateur, essentiel pour l’application pratique sur le terrain.
Post-traitement et génération du masque final
La finalisation du masque implique plusieurs étapes de post-traitement :
– Inversion du masque pour adaptation aux spécificités des images coralliennes
– Redimensionnement selon les dimensions de la bounding box
– Binarisation avec application du seuil optimal déterminé
– Conversion RGBA avec gestion de la transparence via canal alpha
Le processus de suppression du background utilise une transformation conditionnelle du canal alpha :
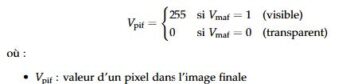
Cette approche préserve l’intégrité chromatique du corail tout en éliminant efficacement l’arrière-plan.

Figure 2 : Corail segmenté sur fond transparent
Identification de l’état de santé du corail
Une fois la segmentation des colonies de corail effectuée, il devient envisageable d’estimer leur taux de blanchissement. Toutefois, cette opération ne peut être menée de manière fiable sans une évaluation préalable de l’état de santé du corail. En effet, cette mesure n’a de sens que pour les coraux encore vivants ou déjà morts.
Dans ce contexte, nous avons développé un algorithme de classification d’images basé sur des modèles de vision par ordinateur, capable d’identifier automatiquement l’état de santé de chaque colonie. Ce classificateur distingue trois états biologiques :
– Sain : le corail présente une pigmentation normale.
– Blanchi : le corail a perdu une partie ou la totalité de ses pigments, Il est encore vivant, mais vulnérable.
– Mort : le corail ne présente plus de tissu vivant.
L’objectif de cette classification est de s’assurer que l’analyse du blanchissement ne soit appliquée qu’aux coraux vivants (sain ou blanchi).

Figure 3 : Illustration d’image de coraux blanchi, mort et sain
Data augmentation
Après la labélisation des images, nous avons observé un déséquilibre entre les différentes classes.

Figure 4 : Diagramme de la répartition des images dans le dataset de base
Pour y remédier, nous avons appliqué une technique avancée de data augmentation appelée Mixup intra-classe qui permet d’augmenter la diversité des données. Cette méthode favorise un apprentissage plus robuste. Grâce à cette augmentation, notre jeu de données initial de 6 000 images a été enrichi, atteignant désormais plus de 10 000 images.

Figure 5 : Diagramme de la répartition des images après data augmentation
Entraînement des modèles
Afin d’obtenir les meilleures performances, nous avons testé plusieurs :
– Modèles (CNN, ViT)
– Valeurs pour le learning rate
– Techniques de fine-tuning (dégeler les couches, custom head)
Modèle sélectionné

Figure 6 : Architecture du modèle DenseNet 201
Nous avons opté pour l’architecture DenseNet201. Le dataset a été divisé en 70 % entraînement, 15 % validation et 15 % test.
L’entraînement s’est déroulé sur 10 epochs avec une stratégie d’early stopping pour éviter le surapprentissage. Un learning rate de 0.0001 a été choisi pour des mises à jour stables des poids, et un weight decay de 0.00001 a été appliqué pour régulariser le modèle. Seules les deux dernières couches du backbone ont été dégelées. Après plusieurs essais, ce paramétrage s’est avéré être la meilleure configuration. Nous avons également testé l’ajout de couches personnalisées (custom heads) pour améliorer les performances. Toutefois, ces modifications n’ont pas apporté de gains significatifs.
Avec cette configuration, le modèle a atteint une précision de 95 % sur le jeu de test, confirmant la pertinence des choix effectués.

Figure 7 : Matrice de confusion du modèle DenseNet2001
Détermination du genre et de l’espèce d’un corail
Après avoir segmenté et classifié l’état de santé du corail de l’image, la dernière étape de notre pipeline de traitement concerne la classification des genres et espèces. Cette étape permettra à l’association de recenser les coraux de façon précise et ainsi guider les actions de conservation.
Notre PoC s’appuie sur l’état de l’art des méthodes de classification d’images similaires à notre problématique. Nous avons étudié les architectures de deep learning les plus performantes. Les Convolutional Neural Networks (CNNs) avec les familles EfficientNet, DenseNet et ResNet, ainsi que les Vision Transformers (ViTs) se sont révélés particulièrement prometteurs.
Nous avons d’abord entraîné les modèles à classer les genres de coraux, afin de sélectionner les architectures les plus adaptées. Sur la base du F1-score, trois modèles se sont démarqués : EfficientNetB3, ResNet50 et DenseNet169.
Ces modèles ont ensuite été intégrés dans deux méthodes pour la classification d’espèces :
– Classification à entraînement progressif : on part d’un modèle pré-entraîné sur ImageNet, affiné sur la tâche de genre, puis réentraîné sur la tâche d’espèce avec pré-entrainement sur le modèle de classification de genre.
– Classification hiérarchique conditionnelle : une première tête prédit le genre, dont le vecteur de probabilité est concaténé aux caractéristiques de l’image, puis transmis à une seconde tête qui prédit l’espèce.

Figure 8 : Pipeline de la méthode de classification à entraînement progressif

Figure 9 : Pipeline de la méthode de classification conditionnelle hiérarchique
Différentes optimisations ont été testées pour améliorer les performances des modèles. Nous avons ajusté les hyperparamètres (nombre de couches dégelées, learning rate, weight decay) utilisé l’augmentation de données et testé la fonction de coût Focal Loss pour mieux gérer le déséquilibre des classes. L’intégration du ground truth dans la classification hiérarchique conditionnelle a aussi été explorée afin d’affiner la précision des prédictions. Ces ajustements ont renforcé la robustesse des modèles.
 vs entraînement progressif (EP).")
Tableau 1 : Comparaison des meilleures configurations de chaque classification et de chaque méthode : classification hiérarchique conditionnelle (CHC) vs entraînement progressif (EP).
Les ViTs ont montré d’excellentes performances pour la classification de genre. En revanche, ils se sont révélés nettement moins efficaces que les CNNs pour la classification d’espèces. Cette différence s’explique probablement par la capacité supérieure des CNNs à capter les détails fins, indispensables pour distinguer des espèces visuellement très proches.
Les résultats du tableau montrent que la classification hiérarchique avec EfficientNetB3 obtient les meilleures performances en termes de F1-score. Des métriques telles que le temps d’inférence et la taille mémoire du modèle ont été analysées en gardant à l’esprit l’objectif final de déployer une application web par l’association.
Nous avons rencontré plusieurs difficultés au cours du projet. La première est le déséquilibre des classes qui a compliqué l’apprentissage des modèles. De plus, un temps important a été consacré à la constitution et à l’amélioration du jeu de données. Enfin, il a fallu faire face aux contraintes computationnelles et aux longs temps d’entraînement des modèles. Le PoC arrive à son terme, mais plusieurs axes d’amélioration restent à explorer pour perfectionner la classification. L’intégration de la segmentation dans le pipeline pourrait permettre de réentraîner les modèles et d’améliorer leurs performances. De plus, il serait intéressant de tester une approche DeiT qui rend l’apprentissage des ViTs plus efficace même avec une base de données limitée. Cette méthode de classification a été observée lors de l’état de l’art. Il faudrait utiliser le meilleur CNN pour la
classification d’espèces afin de distiller l’information vers un Vision Transformer lors de son entraînement.
Fonctionnement global de la solution
Grâce à l’intelligence artificielle, nous avons construit une solution qui accompagne l’utilisateur depuis l’image brute jusqu’à une analyse complète du corail, en fournissant des informations précises sur sa santé, son espèce et son taux de blanchiment.
Tout commence par une action simple : l’utilisateur soumet une photo sous-marine contenant un corail. L’image est d’abord analysée pour identifier et isoler automatiquement le corail. Une fois le corail segmenté, il est classifié en une catégorie parmi ces trois : Sain, Blanchi, Mort. Les coraux morts sont ensuite exclus des étapes suivantes, car leur identification biologique n’est plus possible.
Si le corail est détecté comme blanchi, un algorithme va permettre d’estimer le taux de blanchissement du corail exprimé en pourcentage. Si le corail est détecté comme sain ou blanchi un algorithme va déterminer son genre et son espèce. À partir des caractéristiques visuelles (forme, structure, texture), un modèle de classification compare le corail à une base d’espèces connues. Cette étape permet de mieux comprendre quelles espèces sont les plus touchées par le blanchissement et de suivre leur évolution.
À la fin de ce processus, l’utilisateur reçoit une fiche d’analyse contenant : L’état de santé du corail (sain, blanchi, ou mort), le taux de blanchissement, le genre et l’espèce du corail, ainsi que l’image segmentée du corail analysé.
Conclusion
Ce type de solution peut être intégré dans des outils de monitoring automatisé afin de suivre l’évolution des récifs en continu. L’utilisateur n’aura qu’un seul rôle : charger l’image du corail qu’il veut analyser et notre solution s’occupe de tout. Ce travail montre concrètement comment l’intelligence artificielle peut devenir un allié puissant pour la biodiversité, en aidant les chercheurs et les ONG à surveiller et préserver les écosystèmes marins.
